3.2. Data Understanding#
Wir haben betont, dass Geschäftsprobleme gelöst werden müssen in der Realität. Jedoch können wir Analyse-Algorithmen nur auf Daten anwenden, die diese Realität abbilden. Eine solche Abbildung ist im Allgemeinen nicht vollständig und nicht von perfekter Qualität. In dieser Phase geht es darum Geschäftsverständnis und die Daten in Einklang zu bringen.
Im Folgenden betrachten wir die einzelnen Schritte anhand eines Beispiels in dem die verkaufte Menge Eiscreme in einem Supermarkt anhand historischer Daten vorhergesagt werden soll. Wie bereits in der Einleitung für den gesamten CRISP-DM Prozess beschrieben, gibt es auch hier keine strikte Sequenz der Schritte. Zum Beispiel ergeben sich in der Datenexploration häufig Fragestellungen, deren Beantwortung durch den Geschäftsbereich entweder zu einer Anpassung des Geschäftsverständnis oder zur Entdeckung von Datenqualitätsproblemen führen.
1. Schritt: Datenbeschaffung
Wir erheben welche Daten vorhanden sind und welche noch fehlen. Bei fehlenden Daten gibt es drei prinzipielle Vorgehensweise - illustriert am Beispiel, dass wir Wetterdaten in unser Modell aufnehmen wollen:
Wir akzeptieren, dass die Daten nicht gibt und die daraus resultierenden Einschränkungen der Funktionalität oder Qualität, z.B. könnten wir die Annahme treffen, dass typische Wetter über den Monat angenähert wird
Wir erheben die zusätzlichen Daten, z.B. könnten wir den Fillialleiter beauftragen jeden Tag die Temperatur und den Niederschlag festzuhalten
Wir beschaffen eine zusätzliche Datenquelle, z.B. könnten wir von einem Wetterdienst die Daten hinzukaufen
2. Schritt: Analyse der Datenqualität
Betrachten wir im Folgenden einen Beispieldatensatz, den wir nach der Datenbeschaffung vorliegen haben. Teildatensatz für die erste Woche, 23. und letzte Kalenderwoche:
Show code cell source
import pandas as pd
import numpy as np
from datetime import date
np.random.seed(42)
# Generiere alle Tage in 2021
date_index = pd.date_range(start=date(2021,1,1), end=date(2021,12,31), freq='D')
# Entferne die Sonntage
date_index = date_index[date_index.weekday != 6]
# Erstelle DataFrame mit den Nicht-Sonntagen aus 2021 als Index
ice_sales = pd.DataFrame(index=date_index)
# Füge Wochentage und Namen hinzu
ice_sales['weekday'] = ice_sales.index.weekday
ice_sales['dayname'] = ice_sales.index.day_name()
# Füge Fehler hinzu bei Wochentag 04.01.
ice_sales.loc['2021-01-04', 'dayname'] = 'Tuesday'
# Lösche Datensatz
ice_sales.drop('2021-06-08', inplace=True)
# Random temperatures depending on month
ice_sales['temperature'] = 30 - np.square((ice_sales.index.month - 7).values) + np.random.normal(loc=0.0, scale=0.5, size=len(ice_sales)).cumsum().round(1)
# Cap bei 0 Grad nach unten als Datenfehler Auffälligkeit
ice_sales.loc[ice_sales['temperature'] < 0, 'temperature'] = 0.0
# Eisverkauf je Woche proportional zu Temperatur
ice_sales.groupby(ice_sales.index.month)
ice_sales['ice_sales_eur'] = (1000 * np.square((ice_sales['temperature'] + 25) / 40) + np.random.normal(loc=0.0, scale=15, size=len(ice_sales))).round(2)
# Füge negativen sales bei zweiter Zeile
ice_sales.loc['2021-01-02', 'ice_sales_eur'] = -400.32
# Ausreiser
ice_sales.loc['2021-06-12', 'ice_sales_eur'] = 31432.25
# Encoding Fehler beim letzten Freitag
ice_sales.loc['2021-12-31', 'dayname'] = 'Fri'
# NaN
ice_sales.loc['2021-06-09', 'temperature':'ice_sales_eur'] = np.nan
# Fehler Duplikat
ice_sales = ice_sales.append(ice_sales.loc['2021-12-31'])
ice_sales
rows_to_display = (ice_sales.index <= '2021-01-05') | (ice_sales.index.isocalendar().week == 23) | (ice_sales.index.isocalendar().week == 52)
ice_sales[rows_to_display]
| weekday | dayname | temperature | ice_sales_eur | |
|---|---|---|---|---|
| 2021-01-01 | 4 | Friday | 0.0 | 403.01 |
| 2021-01-02 | 5 | Saturday | 0.0 | -400.32 |
| 2021-01-04 | 0 | Tuesday | 0.0 | 410.21 |
| 2021-01-05 | 1 | Tuesday | 0.0 | 390.94 |
| 2021-06-07 | 0 | Monday | 23.1 | 1451.51 |
| 2021-06-09 | 2 | Wednesday | NaN | NaN |
| 2021-06-10 | 3 | Thursday | 23.5 | 1462.45 |
| 2021-06-11 | 4 | Friday | 23.3 | 1442.17 |
| 2021-06-12 | 5 | Saturday | 23.7 | 31432.25 |
| 2021-12-27 | 0 | Monday | 4.5 | 547.26 |
| 2021-12-28 | 1 | Tuesday | 4.8 | 543.17 |
| 2021-12-29 | 2 | Wednesday | 4.7 | 558.38 |
| 2021-12-30 | 3 | Thursday | 4.6 | 575.83 |
| 2021-12-31 | 4 | Fri | 5.2 | 590.21 |
| 2021-12-31 | 4 | Fri | 5.2 | 590.21 |
Bei der Betrachtung gibt es einige Auffälligkeiten, die auf typische Qualitätsprobleme hinweisen:
Der Name des Wochentags vom 05.01.2021 ist der gleiche wie am 04.01.2021 - dieser Wert kann aus dem Datum berechnet werden und ist hier klar fehlerhaft
Die Temperatur in der ersten Woche ist immer genau 0,0 Grad - es sollte überprüft werden, ob das ein systematischer Fehler ist und Minusgrade immer auf 0,0 Grad beschnitten werden
Der Eintrag für den 08.06.2021 fehlt komplett - für den 09.06.2021 fehlen Temperatur und Eisverkauf
Der Eintrag für den 31.12.2021 ist dupliziert
Der Wochentag für den 31.12.2021 ist anders kodiert als die anderen Wochentage (‘Fri’ vs. ‘Friday’)
Am 02.01.2021 gibt es ein negativen Umsatz mit Eis - es muss überprüft werden, ob das ein Datenfehler ist oder ob es eine geschäftliche Erklärung dafür gibt
Am 12.06.2021 gibt es einen Ausreisser mit sehr hohem Umsatz - falls dies kein Fehler ist, muss besprochen werden, ob der Wert dennoch als Ausnahme ignoriert wird
3. Schritt: Datenexploration
Bei der Datenexploration wird das Verständnis der Datenstruktur, der Daten und des modellierten Geschäftsproblem vertieft. Hier helfen insbesondere die Berechnung von Statistiken (z.B. Mittelwerte, Min, Max) und Visualisierungen (z.B. Histogramme, Boxplots).
Beispielsweise könnten wir uns die Umsatzentwicklung uim Jahresverlauf anzeigen lassen:
Show code cell source
import matplotlib.pyplot as plt
ice_no_outlier = ice_sales[ice_sales.index != '2021-06-12']
ice_no_outlier = ice_no_outlier[ice_no_outlier['ice_sales_eur'] >= 0]
ice_no_outlier = ice_no_outlier.dropna()
fig, ax1 = plt.subplots(figsize=(12,8))
# ax2 = ax1.twinx()
ax1.set_xlabel('Zeit')
ax1.set_ylabel('Umsatz Eiscreme')
ax1.plot(ice_no_outlier.index, ice_no_outlier['ice_sales_eur'])
# ax2.set_ylabel('Temperatur')
# ax2.plot(ice_no_outlier.index, ice_no_outlier['temperature'])
plt.show()
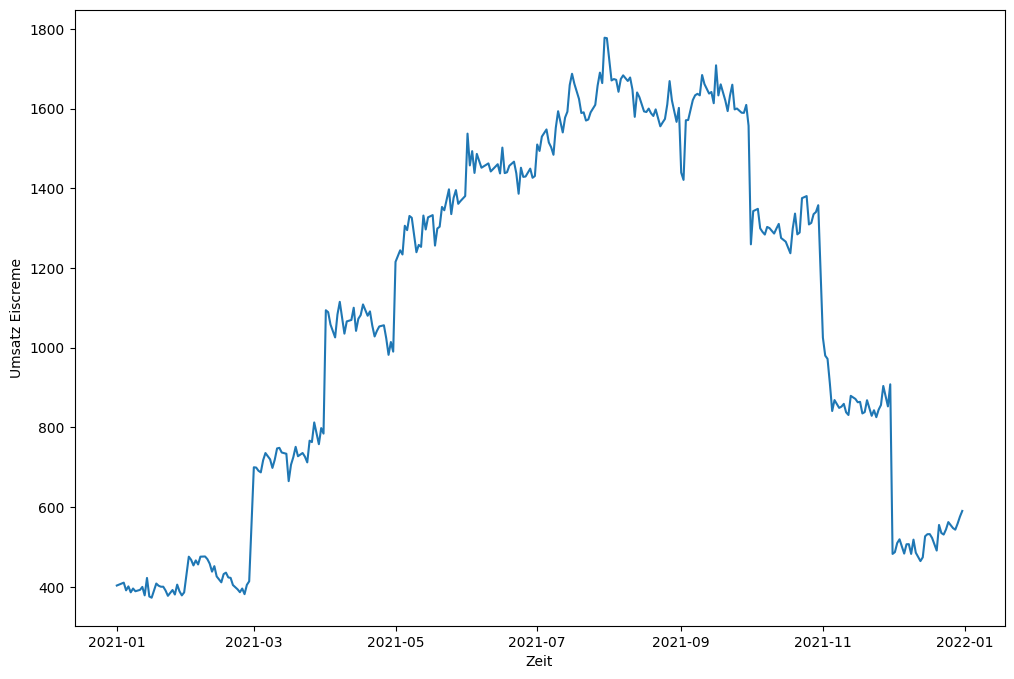
Ebenso können wir uns die Werteverteilung auf Tagesebene als Histogramm anzeigen lassen:
Show code cell source
ice_no_outlier['ice_sales_eur'].hist()
plt.show()
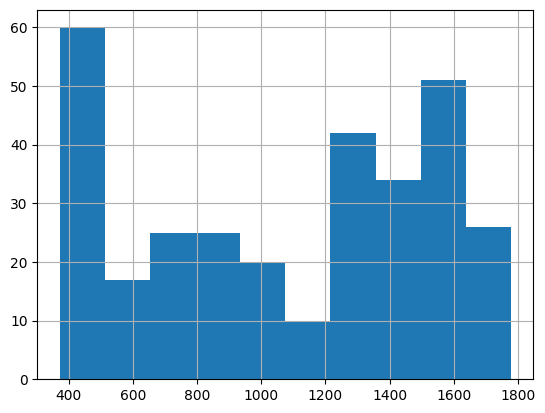
Im Histogramm können wir sehen, dass es sehr viele Verkaufstage im sehr niedrigen Bereich gibt (ca. 400 Euro). Es gibt relativ wenig Verkaufstage im mittleren Bereich von 500 bis 1200 Euro und dann wieder eine Häufung bei den höheren Werten.
4. Schritt: Vereinigung mit Geschäftsverständnis
Die Erkenntnisse aus der Exploration und die Fragen aus der Qualitätskontrolle führen zu einem Dialog mit dem Geschäftsbereich, wo sich nach und nach das Problemverständnis weiterentwickelt. Z.B. kommt vielleicht aus den Daten heraus, dass das Problem das ursprünglich untersucht werden sollte sehr selten vorkommt und daher nicht lohnt.
In unserem Beispiel könnte z.B. sich herausstellen, dass eine Vorhersage auf Wochenebene viel einfacher ist als auf Tagesebene, da sich im Wochenverlauf die einzelnen Tagesschwankungen ausgleichen. In Rücksprache mit dem Fachbereich kommt es zur Einigung, dass eine tagesgenaue Prognose gar nicht notwendig ist, da die Eiscreme nicht verderblich ist und ohnehin nur zwei Mal pro Woche angeliefert wird.