6. Datentransformation#
Bestimmte Auswertungen und Visualisierungen sind viel einfacher, wenn die Daten in einer bestimmten Struktur angeordnet sind. Erste Beispiele haben wir im Kapitel Datenexploration gesehen:
Wenn wir die Daten sortieren, dann ist es einfach auf die größten/kleinsten Einträge zuzugreifen
Wenn wir die Daten gruppieren, dann können wir einfach Statistiken für bestimmte Untergruppen berechnen
Die vorherigen Operationen ordnen die einzelnen Zeilen anders an (sort_values) oder fassen sie zusammen (groupby und agg) lassen aber die generelle Form des DataFrame mehr oder minder in Takt (bei Gruppierungen können Spalten hinzukommen oder wegfallen und der Index verändert werden).
In diesem Kapitel gehen wir auf Methoden ein, die zu DataFrames mit anderem Aufbau führen, z.B.
Beim Pivotieren führen wir im Prinzip eine zweidimensionale Gruppierung durch, so dass aus Werten in Zeilen im Ergebnis Spalten werden (z.B. von einer Zeile pro Transporttyp (Bahn, Bus) zu einer Zeile pro Stadt mit Transporttypen als Spalten)
Mit
melterreichen wir das Gegenteil und machen aus Spalten Werte in Zeilen (z.B. aus 3 Spalten mit den 3 größten Städten pro Land werden 3 Zeilen pro Land mit je einer Stadt)Mit
mergeführen wir unterschiedliche DataFrames in eins zusammen (z.B. aus Datensätzen über Städte und Liniennetze wird ein Datensatz mit mit Infos über beides)
Die Übungen und Beispiele basieren auf Daten über weltweite Systeme des öffentlichen Nahverkehrs von https://www.citylines.co
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
6.1. Datensätze zusammenführen#
Bei der Einführung in pandas haben wir bereits einen Blick auf pd.concat geworfen, um DataFrames “nebeneinander” oder “untereinander” zu packen.
Zur Wiederholung noch mal einfache Beispiele:
dfa = pd.DataFrame({'a': [1, 2, 3], 'b': [4, 5, 6]}, index=[0, 1, 2])
dfa
| a | b | |
|---|---|---|
| 0 | 1 | 4 |
| 1 | 2 | 5 |
| 2 | 3 | 6 |
dfb = pd.DataFrame({'a': [7, 8, 9], 'b': [10, 11, 12]}, index=[3, 4, 5])
dfb
| a | b | |
|---|---|---|
| 3 | 7 | 10 |
| 4 | 8 | 11 |
| 5 | 9 | 12 |
# "Untereinander" zusammenfügen:
dfab = pd.concat([dfa, dfb])
dfab
| a | b | |
|---|---|---|
| 0 | 1 | 4 |
| 1 | 2 | 5 |
| 2 | 3 | 6 |
| 3 | 7 | 10 |
| 4 | 8 | 11 |
| 5 | 9 | 12 |
# "Nebeneinander" zusammenfügen
dfc = pd.DataFrame({'c': [13, 14, 15, 16, 17, 18]})
pd.concat([dfab, dfc], axis=1)
| a | b | c | |
|---|---|---|---|
| 0 | 1 | 4 | 13 |
| 1 | 2 | 5 | 14 |
| 2 | 3 | 6 | 15 |
| 3 | 7 | 10 | 16 |
| 4 | 8 | 11 | 17 |
| 5 | 9 | 12 | 18 |
Die Besonderheit beim letzten Beispiel ist, dass wir a) gleich viele Zeilen in beiden DataFrames haben (dfab und dfc) und die Indexe übereinstimmen. Für generischere Zusammenführungen (nicht nur 1:1, sondern 1:n oder n:m) im Stile von SQL-Joins oder Excel-vlookups gibt es die Methode merge. Siehe den User Guide für umfangreiche Beispiele der einzelnen Methoden.
Wir laden als erstes neben unserer cities-Datenbank drei weitere Datensätze:
lines: enthält die Linien (z.B. S1, Bus 42) der einzelnen Systemetransport_modes: enthält die textuellen Bezichnungen, der verschiedenen Arten von ÖPNV-Systemen (z.B. “tram” (Strassenbahn) oder “bus”)sections: enthält Abschnitte im Liniennetz also z.B. die Schienen zwischen zwei Haltestellensection_lines: enthält die Zuordnung der Abschnitte zur einer Linie, ggfs. mit Einschränkung des Zeitraums
cities = pd.read_csv('data/cities_non_zero.csv', index_col='id')
cities.head()
| name | country | lat | long | start_year | age | length_km | |
|---|---|---|---|---|---|---|---|
| id | |||||||
| 11 | Athens | Greece | 37.966667 | 23.716667 | 1867 | 159 | 86.834 |
| 139 | Boston | United States | 42.350000 | -71.083333 | 1806 | 220 | 615.505 |
| 206 | New York | United States | 40.783333 | -73.966667 | 1817 | 209 | 1089.854 |
| 54 | Helsinki | Finland | 60.166667 | 25.000000 | 2017 | 9 | 0.639 |
| 231 | San Francisco | United States | 37.783333 | -122.433333 | 1863 | 163 | 351.531 |
# Cached version of https://data.heroku.com/dataclips/pzyttqskrypbmrycmyzgfiyiazzj.csv
# Datum: 19.07.2021
lines = pd.read_csv("data/lines.csv", index_col='id')
lines.head()
| city_id | name | url_name | color | system_id | transport_mode_id | |
|---|---|---|---|---|---|---|
| id | ||||||
| 43 | 4 | Línea 2 | 43-linea-2 | #ffbe2e | 267 | 4 |
| 72 | 4 | FFCC Llano del Maipo | 72-ffcc-llanos-del-maipo | #bd10e0 | 478 | 9 |
| 73 | 4 | FFCC Yungay-Barrancas | 73-ffcc-yungay---barranas | #bd10e0 | 478 | 9 |
| 2807 | 215 | Monogahela Street Railway | 2807-monogahela-street-railway | #000 | 793 | 9 |
| 2080 | 22 | Mumbai -Ahmedabad | 2080-mumbai--ahmedabad | #3ab22b | 685 | 1 |
# Cached version of https://data.heroku.com/dataclips/laduqgisvogcjargoqgcvgdjibxl.csv
# Datum: 19.07.2021
transport_modes = pd.read_csv('data/transport_modes.csv', index_col='id')
transport_modes
| name | |
|---|---|
| id | |
| 0 | default |
| 1 | high_speed_rail |
| 2 | inter_city_rail |
| 3 | commuter_rail |
| 4 | heavy_rail |
| 5 | light_rail |
| 6 | brt |
| 7 | people_mover |
| 8 | bus |
| 9 | tram |
| 10 | ferry |
# Cached version of https://data.heroku.com/dataclips/jpimoyzuunvntdmjgheiscrzahls.csv
# Datum: 19.07.2021
sections = pd.read_csv("data/sections.csv", index_col='id')
sections.head()
| geometry | buildstart | opening | closure | length | city_id | |
|---|---|---|---|---|---|---|
| id | ||||||
| 1911 | LINESTRING(19.0817752 47.5005079,19.0817355 47... | 0.0 | 0.0 | 999999.0 | 6719 | 29 |
| 2563 | LINESTRING(16.4151057 48.1907238,16.4156455 48... | 0.0 | 0.0 | 999999.0 | 199 | 118 |
| 2557 | LINESTRING(16.4164437 48.1839655,16.4161534 48... | 0.0 | 0.0 | 999999.0 | 925 | 118 |
| 2558 | LINESTRING(16.4164901 48.1839473,16.416198 48.... | 0.0 | 0.0 | 999999.0 | 881 | 118 |
| 2564 | LINESTRING(16.415259 48.1908074,16.4153634 48.... | 0.0 | 0.0 | 999999.0 | 213 | 118 |
# Cached version of https://data.heroku.com/dataclips/egetzfbhwqhqjbpedplrgppjlerc.csv
# Datum: 19.07.2021
section_lines = pd.read_csv("data/section_lines.csv", index_col='id')
section_lines.head()
| section_id | line_id | created_at | updated_at | city_id | fromyear | toyear | line_group | |
|---|---|---|---|---|---|---|---|---|
| id | ||||||||
| 2494 | 1278 | 343 | 2017-11-21 00:00:00 | 2017-11-21 00:00:00 | 252 | NaN | NaN | 0 |
| 4124 | 4477 | 779 | 2017-11-21 00:09:55.135507 | 2017-11-21 00:09:55.135507 | 63 | NaN | NaN | 0 |
| 2495 | 21 | 9 | 2017-11-21 00:00:00 | 2017-11-21 00:00:00 | 1 | NaN | NaN | 0 |
| 2496 | 940 | 228 | 2017-11-21 00:00:00 | 2017-11-21 00:00:00 | 79 | NaN | NaN | 0 |
| 4129 | 4478 | 793 | 2017-11-21 17:44:39.765832 | 2017-11-21 17:44:39.765832 | 48 | NaN | NaN | 0 |
Die einzelnen Datensätze sind zu einem gewissen Ausmaß normalisiert. Für die Datenanalyse bevorzugen wir im Allgemeinen eine denormalisierte Form, die pro Zeile eine Beobachtung/ein Objekt mit allen zugehörigen Informationen enthält - z.B. eine Stadt mit dem Namen des zugehörigen Landes. Ausnahmen gibt es bei Speichermangel oder insbesondere, wenn die Daten für Machine Learning vorbereitet werden, wo wir bestimmte Daten wieder numerisch ähnlich einem Index kodieren.
Im Folgenden nutzen wir die merge-Methode, um das cities-DataFrame nach und nach mit den Informationen der anderen DataFrames anzureichern. Die merge-Methode wird auf dem linken DataFrame aufgerufen und bekommt als ersten Parameter das rechte DataFrame. Das Ergebnis ist eine Kombination aus linkem und rechtem DataFrame, das entsprechend der weiteren Parameter zusammengesetzt wird:
Mit
onwird eine Spalte angegeben, die in beiden DataFrames vorhanden sein muss - neue Zeilen entstehen aus den Kombinationen aus linken und rechten Zeilen, die in deron-Spalte übereinstimmenMit
left_onundright_onkönnen unterschiedliche Spaltennamen im linken und rechten DataFrame angegeben werdenStatt Spalten kann mit
left_indexundright_indexauch angegeben werden, dass der Index genutzt werden sollStandardmäßig werden nur Zeilen ausgegeben zu denen übereinstimmende Werte in beiden DataFrames existieren (Parameter
how='inner'). Alternativ können alle Zeilen aus dem linken (how='left'), rechten (how='right') oder beiden (how='outer') DataFrames übernommen werden - die fehlenden Daten werden dann mitnp.NaNaufgefüllt.Mit
suffixeskann eine Liste von Strings übergeben werden, die an Spaltennamen gehängt werden, wenn die Namen in beiden DataFrames vorkommen
Als Erstes überlegen wir das Ziel der Analyse: Wir wollen pro Stadt rausfinden, wie viele Kilometer auf verschiedene Transportarten (Schiene, Bus, etc.) fallen.
Wir fangen “unten” bei den Streckenabschnitten an und kommen dann zu den Städten:
# Zusammenfügen von sections und zugehöriger Line
line_sections = sections.merge(section_lines, left_index=True, right_on='section_id', suffixes=['','_sections'])
# Anfügen der Infos aus lines
line_sections = line_sections.merge(lines, left_on='line_id', suffixes=['','_lines'], right_index=True)
line_sections.head()
| geometry | buildstart | opening | closure | length | city_id | section_id | line_id | created_at | updated_at | city_id_sections | fromyear | toyear | line_group | city_id_lines | name | url_name | color | system_id | transport_mode_id | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| id | ||||||||||||||||||||
| 1 | LINESTRING(19.0817752 47.5005079,19.0817355 47... | 0.0 | 0.0 | 999999.0 | 6719 | 29 | 1911 | 530 | 2017-11-21 00:00:00 | 2017-11-21 00:00:00 | 29 | NaN | NaN | 0 | 29 | M4 | 530-m4 | #71be1c | 22 | 5 |
| 2 | LINESTRING(16.4151057 48.1907238,16.4156455 48... | 0.0 | 0.0 | 999999.0 | 199 | 118 | 2563 | 154 | 2017-11-21 00:00:00 | 2017-11-21 00:00:00 | 118 | NaN | NaN | 0 | 118 | U3 | 154-u3 | #f5a623 | 251 | 0 |
| 3 | LINESTRING(16.4164437 48.1839655,16.4161534 48... | 0.0 | 0.0 | 999999.0 | 925 | 118 | 2557 | 154 | 2017-11-21 00:00:00 | 2017-11-21 00:00:00 | 118 | NaN | NaN | 0 | 118 | U3 | 154-u3 | #f5a623 | 251 | 0 |
| 4 | LINESTRING(16.4164901 48.1839473,16.416198 48.... | 0.0 | 0.0 | 999999.0 | 881 | 118 | 2558 | 154 | 2017-11-21 00:00:00 | 2017-11-21 00:00:00 | 118 | NaN | NaN | 0 | 118 | U3 | 154-u3 | #f5a623 | 251 | 0 |
| 5 | LINESTRING(16.415259 48.1908074,16.4153634 48.... | 0.0 | 0.0 | 999999.0 | 213 | 118 | 2564 | 154 | 2017-11-21 00:00:00 | 2017-11-21 00:00:00 | 118 | NaN | NaN | 0 | 118 | U3 | 154-u3 | #f5a623 | 251 | 0 |
Nun können wir die Abschnitte auf Transport-Modus-Ebene agreggieren. Dabei filtern wir auch alle Zuordnungen raus, die entweder ein Startdatum (fromyear) in der Zukunft oder ein Enddatum (toyear) in der Vergangenheit haben. Ebenso gehen wir bei opening und closing der Sections vor. Da wir hier viele NaN-Werte haben ersetzen wir mit passenden “Randwerten”.
# Ersetzen der NaNs mit passenden Randwerten
# Wir wählen die Werte so, dass bei NaN angenommen wird:
# - die Zuordnung besteht schon immer (Jahr 0)
# - und bis in alle Ewigkeit (Jahr 9999)
line_sections['fromyear'].fillna(value=0, inplace=True)
line_sections['toyear'].fillna(value=9999, inplace=True)
# Ausfiltern der Zuordnungen, die nicht aktuell sind
year = 2021
line_sections = line_sections[(line_sections['fromyear'] <= year) & (line_sections['toyear'] >= year)]
# Gleiches Vorgehen bezüglich opening und closing der sections
line_sections['opening'].fillna(value=0, inplace=True)
line_sections['closure'].fillna(value=9999, inplace=True)
# Ausfiltern der Sections, die nicht aktuell sind
year = 2021
line_sections = line_sections[(line_sections['opening'] <= year) & (line_sections['closure'] >= year)]
# Reduzieren des Datensatzes auf Stadt, Section und Transport-Modus
# Entfernen von Duplikaten - ein Abschnitt kann von Mehreren Linien
# befahren werden und würde sonst doppelt gezählt
line_sections = line_sections[['city_id', 'section_id', 'transport_mode_id', 'length']].drop_duplicates()
# Aggregation auf Transport-Modus-Ebene
mode_lengths = line_sections.groupby(['city_id', 'transport_mode_id'], as_index=False).agg({'length': 'sum'})
mode_lengths.head()
| city_id | transport_mode_id | length | |
|---|---|---|---|
| 0 | 1 | 3 | 900695 |
| 1 | 1 | 4 | 56177 |
| 2 | 1 | 5 | 19664 |
| 3 | 1 | 6 | 112686 |
| 4 | 1 | 9 | 8408 |
Nun fügen wir die Labels der Transport-Modi hinzu:
mode_lengths = mode_lengths.merge(transport_modes, left_on='transport_mode_id', right_index=True)
mode_lengths.rename(columns={'name': 'transport_mode'},inplace=True)
mode_lengths.drop(columns=['transport_mode_id'],inplace=True)
mode_lengths.head()
| city_id | length | transport_mode | |
|---|---|---|---|
| 0 | 1 | 900695 | commuter_rail |
| 6 | 4 | 81963 | commuter_rail |
| 13 | 13 | 50938 | commuter_rail |
| 17 | 14 | 283422 | commuter_rail |
| 21 | 15 | 350597 | commuter_rail |
Und schließlich die Transportmodi an die Städte:
city_modes = cities.merge(mode_lengths, left_index=True,right_on='city_id')
city_modes.head()
| name | country | lat | long | start_year | age | length_km | city_id | length | transport_mode | |
|---|---|---|---|---|---|---|---|---|---|---|
| 12 | Athens | Greece | 37.966667 | 23.716667 | 1867 | 159 | 86.834 | 11 | 86834 | heavy_rail |
| 165 | Boston | United States | 42.350000 | -71.083333 | 1806 | 220 | 615.505 | 139 | 502893 | commuter_rail |
| 166 | Boston | United States | 42.350000 | -71.083333 | 1806 | 220 | 615.505 | 139 | 65803 | heavy_rail |
| 167 | Boston | United States | 42.350000 | -71.083333 | 1806 | 220 | 615.505 | 139 | 39321 | light_rail |
| 168 | Boston | United States | 42.350000 | -71.083333 | 1806 | 220 | 615.505 | 139 | 4502 | brt |
Hier sehen wir schon einen Nachteil der denormalisierten Daten: die Gesamtlänge (length_km) des Systems der Stadt wird zu jeder Transportart gespeichert:
Man muss sich merken, bzw. dokumentieren, dass die Länge sich auf die gesamte Stadt und nicht auf das System bezieht
Bei einer Aggregation, darf man keinesfalls die Summe der Längen bilden
Ferner ist zu beachten, dass ein Eintrag im DataFrame jetzt keine Stadt mehr beschreibt, sondern viel mehr eine Kombination aus Stadt und Transport-Modus.
Nun haben wir eine Tabelle, die wie gewünscht die Länge pro Transport-Modus je Stadt hat.
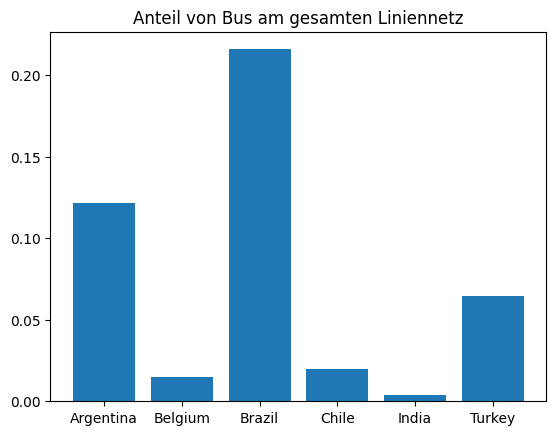
Erstellen Sie Bar-Chart , das den Anteil der verschiedenen Transport-Modi je Land darstellt. Gehen Sie wie folgt vor:
- Erstellen Sie einen Datensatz mit der Gesamtlänge pro Land indem Sie nach Ländern gruppieren
- Mergen Sie den neuen Datensatz mit einer Version von sich selbst, wo über alle Transport-Modi hinweg gruppiert wird
- Erstellen Sie ein Bar-Chart, das den Anteil von `bus` am Gesamtsystem je Land ausgibt
#
Show code cell content
# 1.
country_lengths = city_modes.groupby(['country', 'transport_mode'], as_index=False).agg({'length': 'sum'})
country_lengths.head()
| country | transport_mode | length | |
|---|---|---|---|
| 0 | Argentina | brt | 132188 |
| 1 | Argentina | bus | 193088 |
| 2 | Argentina | commuter_rail | 957884 |
| 3 | Argentina | ferry | 44349 |
| 4 | Argentina | heavy_rail | 56177 |
Show code cell content
# 2.
country_lengths_total = country_lengths.groupby('country', as_index=False).agg({'length': 'sum'})
country_lengths = country_lengths.merge(country_lengths_total, on='country', suffixes=['', '_total'])
Show code cell content
# 3.
country_lengths['share'] = country_lengths['length'] / country_lengths['length_total']
fig, ax = plt.subplots()
bus = country_lengths[country_lengths['transport_mode'] == 'bus']
ax.bar(bus['country'], bus['share'])
ax.set_title('Anteil von Bus am gesamten Liniennetz')
plt.show()
6.2. Pivottabellen#
In der vorherigen Gruppierung haben wir zwar ggfs. mehrere Linien und Abschnitte pro Stadt zusammengefasst, aber wir haben immer noch mehrere Zeilen je Stadt. Um das umgehen verwenden wir die Methode pivot_table (API Referenz). Diese Methode ist am ähnlichsten zu dem, was viele Benutzer aus Excel oder Business-Intelligence-Tools kennen - es gibt auch die Methoden pivot und stack auf denen pivot_table teilweise aufbaut. Der User Guide geht auf genauer auf die Verwendung ein.
Vereinfacht gesagt kann hier zweidimensional gruppiert werden:
per
index-Parameter wird angegeben welche Spalte(n) gruppiert werden sollen, um als Zeilen-Labels verwendet zu werdenper
columns-Parameter wird angeben welche Spalte(n) gruppiert werden sollen, um als Spaltennamen verwendet zu werdenper
valueswird angebenen aus welcher Spalte die Werte zur Aggregation geholt werden sollenper
aggfuncwird angegeben wie die Werte aggregiert werden sollen
Beispiel:
city_modes.pivot_table(index='name', columns='transport_mode', values='length', aggfunc='sum').head()
| transport_mode | brt | bus | commuter_rail | default | ferry | heavy_rail | high_speed_rail | inter_city_rail | light_rail | people_mover | tram |
|---|---|---|---|---|---|---|---|---|---|---|---|
| name | |||||||||||
| Amsterdam | NaN | NaN | NaN | NaN | NaN | 42100.0 | NaN | NaN | NaN | NaN | 571.0 |
| Angers | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 24251.0 | NaN | NaN |
| Athens | NaN | NaN | NaN | NaN | NaN | 86834.0 | NaN | NaN | NaN | NaN | NaN |
| Atlanta | NaN | NaN | NaN | NaN | NaN | 79456.0 | NaN | NaN | NaN | NaN | 4212.0 |
| Austin | NaN | NaN | 51691.0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
In der Tabelle sehen wir viele NaN Werte - immer wenn zur Kombination Stadt und Transportmodus keine Werte vorliegen. Je nach Anwendung bietet es sich hier an einene konstanten Wert einzusetzen. In unserem Fall erscheint eine Länge von 0 als sinnvoll:
city_system_lengths = city_modes.pivot_table(index='name', columns='transport_mode',
values='length', aggfunc='sum',
fill_value=0.0)
city_system_lengths.head()
| transport_mode | brt | bus | commuter_rail | default | ferry | heavy_rail | high_speed_rail | inter_city_rail | light_rail | people_mover | tram |
|---|---|---|---|---|---|---|---|---|---|---|---|
| name | |||||||||||
| Amsterdam | 0 | 0 | 0 | 0 | 0 | 42100 | 0 | 0 | 0 | 0 | 571 |
| Angers | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 24251 | 0 | 0 |
| Athens | 0 | 0 | 0 | 0 | 0 | 86834 | 0 | 0 | 0 | 0 | 0 |
| Atlanta | 0 | 0 | 0 | 0 | 0 | 79456 | 0 | 0 | 0 | 0 | 4212 |
| Austin | 0 | 0 | 51691 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
An dieser Stelle bietet sich ein Test an, ob die Daten konsistent und unsere bisherigen Schritte korrekt waren. Wir wollen die Summe über alle Transportarten (generiert aus den lines und sections Tabellen) mit der Gesamtlänge im DataFrame cities vergleich. Wir kennen bereits die .sum()-Methode:
city_system_lengths.sum()
transport_mode
brt 938070
bus 426751
commuter_rail 9856374
default 4059020
ferry 96754
heavy_rail 15386741
high_speed_rail 889352
inter_city_rail 962465
light_rail 2482765
people_mover 234834
tram 473890
dtype: int64
Hierbei handelt es sich jedoch um die zeilenweisen Summen über alle Städte. .sum() nimmt einen Axis-Parameter und der ist als default immer 0/’rows’. Hier wollen wir jedoch die Summe über alle Spalten:
city_system_lengths['total'] = city_system_lengths.sum(axis='columns')
city_system_lengths.head()
| transport_mode | brt | bus | commuter_rail | default | ferry | heavy_rail | high_speed_rail | inter_city_rail | light_rail | people_mover | tram | total |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| name | ||||||||||||
| Amsterdam | 0 | 0 | 0 | 0 | 0 | 42100 | 0 | 0 | 0 | 0 | 571 | 42671 |
| Angers | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 24251 | 0 | 0 | 24251 |
| Athens | 0 | 0 | 0 | 0 | 0 | 86834 | 0 | 0 | 0 | 0 | 0 | 86834 |
| Atlanta | 0 | 0 | 0 | 0 | 0 | 79456 | 0 | 0 | 0 | 0 | 4212 | 83668 |
| Austin | 0 | 0 | 51691 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 51691 |
# Anpassen der Längen auf km um Vergleichbarkeit zu cities-Tabelle herzustellen
city_system_lengths /= 1000.0
# Mergen der `lengths_km` aus der cities Tabelle. Wir haben keine city_id also über Namen der Stadt
city_system_lengths = city_system_lengths.merge(cities[['name', 'length_km']], left_index=True,right_on='name')
city_system_lengths.head()
| brt | bus | commuter_rail | default | ferry | heavy_rail | high_speed_rail | inter_city_rail | light_rail | people_mover | tram | total | name | length_km | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| id | ||||||||||||||
| 8 | 0.0 | 0.0 | 0.000 | 0.0 | 0.0 | 42.100 | 0.0 | 0.0 | 0.000 | 0.0 | 0.571 | 42.671 | Amsterdam | 42.143 |
| 275 | 0.0 | 0.0 | 0.000 | 0.0 | 0.0 | 0.000 | 0.0 | 0.0 | 24.251 | 0.0 | 0.000 | 24.251 | Angers | 24.251 |
| 11 | 0.0 | 0.0 | 0.000 | 0.0 | 0.0 | 86.834 | 0.0 | 0.0 | 0.000 | 0.0 | 0.000 | 86.834 | Athens | 86.834 |
| 131 | 0.0 | 0.0 | 0.000 | 0.0 | 0.0 | 79.456 | 0.0 | 0.0 | 0.000 | 0.0 | 4.212 | 83.668 | Atlanta | 83.668 |
| 132 | 0.0 | 0.0 | 51.691 | 0.0 | 0.0 | 0.000 | 0.0 | 0.0 | 0.000 | 0.0 | 0.000 | 51.691 | Austin | 51.691 |
city_system_lengths['diff_abs'] = (city_system_lengths['total'] - city_system_lengths['length_km']).abs()
# Anzeige der 10 Städte mit der größten Differenz
city_system_lengths[['name', 'total', 'length_km', 'diff_abs']].sort_values('diff_abs', ascending=False).head(10)
| name | total | length_km | diff_abs | |
|---|---|---|---|---|
| id | ||||
| 54 | Helsinki | 306.087 | 0.639 | 305.448 |
| 69 | London | 1912.358 | 1663.529 | 248.829 |
| 356 | Seoul | 1621.008 | 1418.234 | 202.774 |
| 48 | Glasgow | 360.190 | 528.652 | 168.462 |
| 4 | Santiago | 320.999 | 221.576 | 99.423 |
| 86 | Nanjing | 475.809 | 389.464 | 86.345 |
| 71 | Madrid | 662.591 | 577.574 | 85.017 |
| 22 | Mumbai | 675.341 | 601.802 | 73.539 |
| 37 | Chongqing | 431.529 | 375.405 | 56.124 |
| 149 | Cleveland | 61.491 | 7.430 | 54.061 |
Wie wir sehen sind hier teilweise größere Differenzen für einzelne Städte. Das ist ein durchaus typisches Phänomen bei Datensätzen, die sowohl die Detaildaten (Länge aller Sections und (indirekte) Zuordnung zu Städten) als auch schon aggregierte Daten beinhalten (Länge in cities DataFrame). Dies kann verschiedene Ursachen haben:
Aggregierte Daten wurden nicht aktualisiert, nachdem Detaildaten verändert wurden
Unterschiedliche Berechnungsweisen - wir haben hier schon einiges an Annahmen reingesteckt, z.B. bzgl. Opening, Closure und Section Zuordnungsdaten. Diese können von der Berechnung des Datenproviders abweichen
Da die Abweichung auf das gesamte Datenset recht gering ist, akzeptieren wir diese Abweichung. Bis zu welchem Wert etwas gering oder akzeptabel ist. Da es uns hier nur um die Verteilung zwischen den Transportarten geht und nicht um die absoluten Werte sind wir recht grosszügig.
print(f'Abweichungen über alle Städte {city_system_lengths["diff_abs"].sum() / city_system_lengths["total"].sum() * 100:.2f} %')
Abweichungen über alle Städte 5.04 %
Sollten wir höhere Präzision brauchen können wir je nach konkreter Situation:
Explorative Datenanalyse der Städte mit größter Abweichung, um Ursachen einzugrenzen
Klärung der Berechnungslogik oder bekannter Abweichung mit Anbieter der Daten
Untersuchung des Codes, der die Daten berechnet
Wir speichern das erzeugte DataFrame in die Datei city_system_lengths.csv:
city_system_lengths.drop(columns=['length_km', 'diff_abs']).to_csv('data/city_system_lengths.csv')
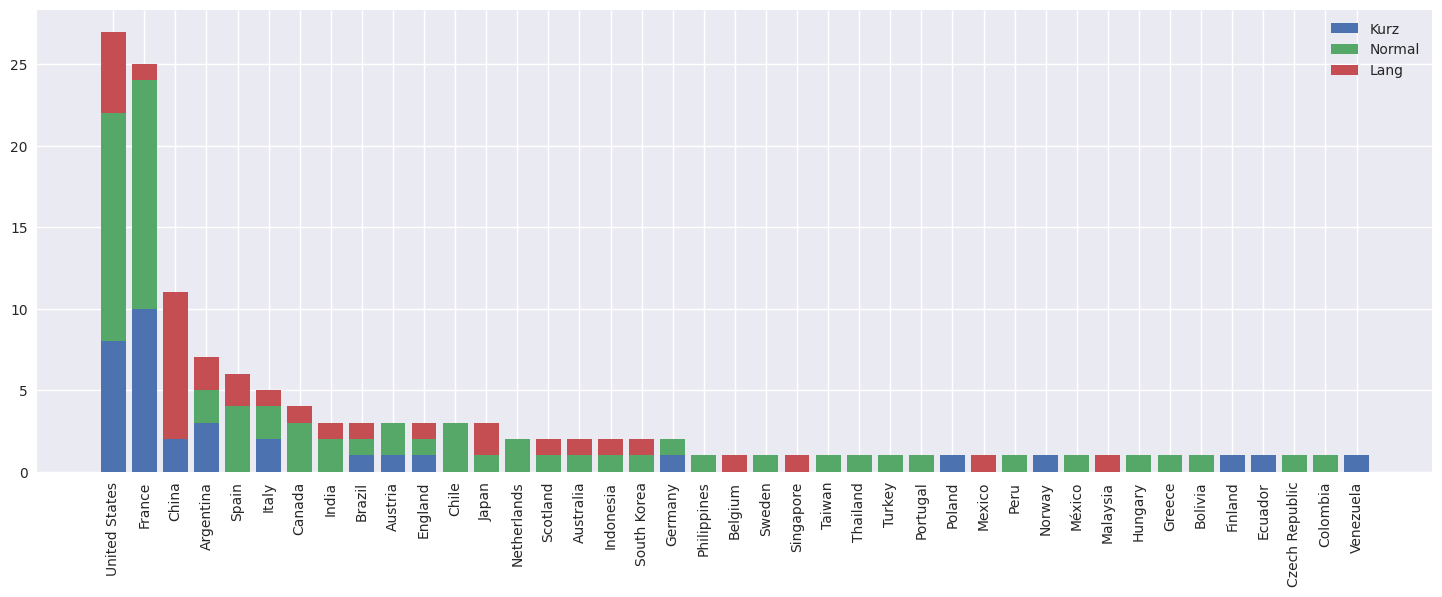
- Erstellen Sie eine neue Spalte in cities, das die Längen in Kategorien einteilt ('kurz', wenn im unteresten Quartil, 'normal', wenn im 2. oder 3. Quartil, sonst 'lang')
- Erstellen Sie eine Pivot-Tabelle mit Ländern als Zeilen und Längenkategorien als Spalten - die Werte soll die Anzahl der Städte sein
- Erstellen Sie ein stacked Bar Chart
#
Show code cell content
# 1.
cities['length_cat'] = 'kurz'
cities.loc[cities['length_km'] >= cities['length_km'].quantile(0.25), 'length_cat'] = 'normal'
cities.loc[cities['length_km'] > cities['length_km'].quantile(0.75), 'length_cat'] = 'lang'
cities.head()
| name | country | lat | long | start_year | age | length_km | length_cat | |
|---|---|---|---|---|---|---|---|---|
| id | ||||||||
| 11 | Athens | Greece | 37.966667 | 23.716667 | 1867 | 159 | 86.834 | normal |
| 139 | Boston | United States | 42.350000 | -71.083333 | 1806 | 220 | 615.505 | lang |
| 206 | New York | United States | 40.783333 | -73.966667 | 1817 | 209 | 1089.854 | lang |
| 54 | Helsinki | Finland | 60.166667 | 25.000000 | 2017 | 9 | 0.639 | kurz |
| 231 | San Francisco | United States | 37.783333 | -122.433333 | 1863 | 163 | 351.531 | lang |
Show code cell content
# 2.
lengths_cats = cities.pivot_table(index='country', columns='length_cat', values='name', aggfunc='nunique', fill_value=0)
lengths_cats.head()
| length_cat | kurz | lang | normal |
|---|---|---|---|
| country | |||
| Argentina | 3 | 2 | 2 |
| Australia | 0 | 1 | 1 |
| Austria | 1 | 0 | 2 |
| Belgium | 0 | 1 | 0 |
| Bolivia | 0 | 0 | 1 |
Show code cell content
# 3.
plt.style.use('seaborn')
fig, ax = plt.subplots(figsize=(18,6))
lengths_cats['total'] = lengths_cats.sum(axis=1)
lengths_cats.sort_values('total', ascending=False, inplace=True)
ax.bar(lengths_cats.index, lengths_cats['kurz'], label='Kurz')
ax.bar(lengths_cats.index, lengths_cats['normal'], bottom=lengths_cats['kurz'], label='Normal')
ax.bar(lengths_cats.index, lengths_cats['lang'], bottom=lengths_cats['kurz']+lengths_cats['normal'], label='Lang')
ax.set_xticklabels(lengths_cats.index, rotation=90)
plt.legend()
plt.show()
/builds/speiser/vl-data-analytics/venv/lib/python3.7/site-packages/ipykernel_launcher.py:9: UserWarning: FixedFormatter should only be used together with FixedLocator
if __name__ == "__main__":
6.3. Spalten in Zeilen umwandeln (melt)#
Die umgekehrte Operation zum Pivotieren ist melt. Hierbei können Werte in Spalten in separate Zeilen umgewandelt werden. Standardmäßig werden alle Spalten zu Zeilen gemacht - der ursprüngliche Zeilenverbund geht verloren. Mit dem Parameter id_vars können Spalten angeben werden, die weiterhin als Spalten übernommen werden und die Zusammengehörigkeit verschiedener Spalten herstellt.
Das einfachste Beispiel ist, wenn wir eine vorherige Pivotierung rückgänging machen:
pivoted = city_system_lengths.drop(columns=['total', 'length_km', 'diff_abs'])
pivoted.head()
| brt | bus | commuter_rail | default | ferry | heavy_rail | high_speed_rail | inter_city_rail | light_rail | people_mover | tram | name | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| id | ||||||||||||
| 8 | 0.0 | 0.0 | 0.000 | 0.0 | 0.0 | 42.100 | 0.0 | 0.0 | 0.000 | 0.0 | 0.571 | Amsterdam |
| 275 | 0.0 | 0.0 | 0.000 | 0.0 | 0.0 | 0.000 | 0.0 | 0.0 | 24.251 | 0.0 | 0.000 | Angers |
| 11 | 0.0 | 0.0 | 0.000 | 0.0 | 0.0 | 86.834 | 0.0 | 0.0 | 0.000 | 0.0 | 0.000 | Athens |
| 131 | 0.0 | 0.0 | 0.000 | 0.0 | 0.0 | 79.456 | 0.0 | 0.0 | 0.000 | 0.0 | 4.212 | Atlanta |
| 132 | 0.0 | 0.0 | 51.691 | 0.0 | 0.0 | 0.000 | 0.0 | 0.0 | 0.000 | 0.0 | 0.000 | Austin |
pivoted.melt(id_vars=['name'])
| name | variable | value | |
|---|---|---|---|
| 0 | Amsterdam | brt | 0.000 |
| 1 | Angers | brt | 0.000 |
| 2 | Athens | brt | 0.000 |
| 3 | Atlanta | brt | 0.000 |
| 4 | Austin | brt | 0.000 |
| ... | ... | ... | ... |
| 1502 | Warsaw | tram | 0.000 |
| 1503 | Washington | tram | 0.000 |
| 1504 | Winnipeg | tram | 0.000 |
| 1505 | Wuhan | tram | 16.842 |
| 1506 | Zaragoza | tram | 18.789 |
1507 rows × 3 columns
Schauen wir uns komplexeres Beispiel an: die geometrischen Punkte der Sections. Diese sind als String abgespeichert, wo die einzelnen Punkte per Komma separiert sind. Um die einzelnen Koordinaten zu bekommen, können wir per .str.split die Koordinaten in Spalten umwandeln und dann mit melt eine Zeile pro Koordinate bilden:
sections.head()
| geometry | buildstart | opening | closure | length | city_id | |
|---|---|---|---|---|---|---|
| id | ||||||
| 1911 | LINESTRING(19.0817752 47.5005079,19.0817355 47... | 0.0 | 0.0 | 999999.0 | 6719 | 29 |
| 2563 | LINESTRING(16.4151057 48.1907238,16.4156455 48... | 0.0 | 0.0 | 999999.0 | 199 | 118 |
| 2557 | LINESTRING(16.4164437 48.1839655,16.4161534 48... | 0.0 | 0.0 | 999999.0 | 925 | 118 |
| 2558 | LINESTRING(16.4164901 48.1839473,16.416198 48.... | 0.0 | 0.0 | 999999.0 | 881 | 118 |
| 2564 | LINESTRING(16.415259 48.1908074,16.4153634 48.... | 0.0 | 0.0 | 999999.0 | 213 | 118 |
# Slice entfernt "LINESTRING" und die schliessende Klammer
# Split erzeugt eine neue Spalte
section_paths = sections['geometry'].str.slice(11,-1).str.split(',', expand=True)
section_paths.head()
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ... | 661 | 662 | 663 | 664 | 665 | 666 | 667 | 668 | 669 | 670 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| id | |||||||||||||||||||||
| 1911 | 19.0817752 47.5005079 | 19.0817355 47.5004893 | 19.0807974 47.5000068 | 19.0803989 47.4998011 | 19.079491 47.4991458 | 19.0791327 47.4986762 | 19.0772964 47.4955602 | 19.0766446 47.4945492 | 19.0760385 47.49405 | 19.0752771 47.493605 | ... | None | None | None | None | None | None | None | None | None | None |
| 2563 | 16.4151057 48.1907238 | 16.4156455 48.190389 | 16.4170845 48.1895171 | None | None | None | None | None | None | None | ... | None | None | None | None | None | None | None | None | None | None |
| 2557 | 16.4164437 48.1839655 | 16.4161534 48.1836515 | 16.4158173 48.1833488 | 16.4155745 48.1831673 | 16.4153602 48.1830237 | 16.4151342 48.1828881 | 16.4148982 48.1827604 | 16.4146926 48.1826603 | 16.4144833 48.1825675 | 16.4142825 48.1824861 | ... | None | None | None | None | None | None | None | None | None | None |
| 2558 | 16.4164901 48.1839473 | 16.416198 48.1836313 | 16.4158591 48.1833262 | 16.4156137 48.1831427 | 16.4153974 48.1829977 | 16.4151692 48.1828607 | 16.414931 48.182732 | 16.4147234 48.1826309 | 16.4145123 48.1825371 | 16.4143219 48.1824491 | ... | None | None | None | None | None | None | None | None | None | None |
| 2564 | 16.415259 48.1908074 | 16.4153634 48.190746 | 16.4156079 48.1905985 | 16.4162929 48.1901825 | 16.4167818 48.189893 | 16.4171761 48.1896436 | 16.417375 48.1895146 | None | None | None | ... | None | None | None | None | None | None | None | None | None | None |
5 rows × 671 columns
# Nun wandeln wir Spalten in Zeilen um
# Die Spaltennamen werden nun die Reihenfolge der Punkte
# In der gleichen Zeile entfernen wir None Werte - diese
# entstehen weil die Anzahl der Spalten nach der Section
# mit den meisten Punkten bestimmt wurde
section_paths = section_paths.melt(ignore_index=False).dropna()
# section_id aus Index in Spalte
section_paths.reset_index(inplace=True)
section_paths.head()
| id | variable | value | |
|---|---|---|---|
| 0 | 1911 | 0 | 19.0817752 47.5005079 |
| 1 | 2563 | 0 | 16.4151057 48.1907238 |
| 2 | 2557 | 0 | 16.4164437 48.1839655 |
| 3 | 2558 | 0 | 16.4164901 48.1839473 |
| 4 | 2564 | 0 | 16.415259 48.1908074 |
# Nun splitten wir nach long und lat
long_lats = section_paths['value'].str.split(' ', expand=True)
# Convert long/lat to number or NaN if not a valid number and add to DataFrame
section_paths['long'] = pd.to_numeric(long_lats[0], errors='coerce')
section_paths['lat'] = pd.to_numeric(long_lats[1], errors='coerce')
# Drop errors
section_paths.dropna(inplace=True)
# Drop Textual Column
section_paths.drop(columns=['value'], inplace=True)
# Und sortieren erst nach id und Variable
section_paths.sort_values(['id', 'variable'], inplace=True)
section_paths.head()
| id | variable | long | lat | |
|---|---|---|---|---|
| 4975 | 1 | 0 | -58.370957 | -34.608837 |
| 20811 | 1 | 1 | -58.372118 | -34.608896 |
| 35819 | 1 | 2 | -58.372376 | -34.608895 |
| 48443 | 1 | 3 | -58.372557 | -34.608889 |
| 59737 | 1 | 4 | -58.372704 | -34.608863 |
# Benennen der Spalten
section_paths.columns = ['section_id', 'order', 'long', 'lat']
section_paths.head()
| section_id | order | long | lat | |
|---|---|---|---|---|
| 4975 | 1 | 0 | -58.370957 | -34.608837 |
| 20811 | 1 | 1 | -58.372118 | -34.608896 |
| 35819 | 1 | 2 | -58.372376 | -34.608895 |
| 48443 | 1 | 3 | -58.372557 | -34.608889 |
| 59737 | 1 | 4 | -58.372704 | -34.608863 |
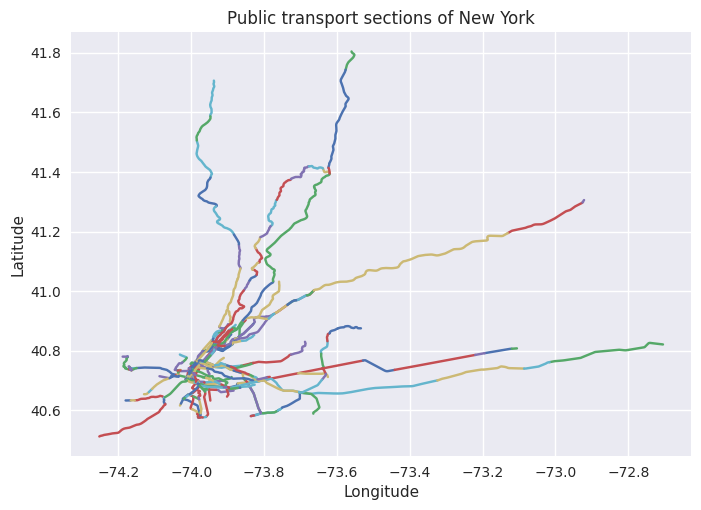
Die matplotlib Funktion plot zeichnet Linien entlang Punkten, wenn als erster Parameter, die x-Koordinaten und als zweiter Parameter, die y-Koordinaten übergeben werden. Dies nutzen wir, indem wir für eine Section sämtliche Koordinaten auswählen, dann das Array transposen und mit dem *-Operator die Einträge als Parameter zur Plot-Funktion übergeben. Wir schreiben eine Funktion, die dies für alle Sections einer gegebenen Stadt macht:
# Draw Sections of City by name
def draw_sections(cityname):
city_id = cities[cities['name'] == cityname].index.values[0]
for section_id in sections[sections['city_id'] == city_id].index:
plt.plot(*section_paths.loc[section_paths['section_id'] == section_id, 'long':'lat'].values.T)
plt.title('Public transport sections of ' + cityname)
plt.xlabel('Longitude')
plt.ylabel('Latitude')
plt.show()
draw_sections('London')
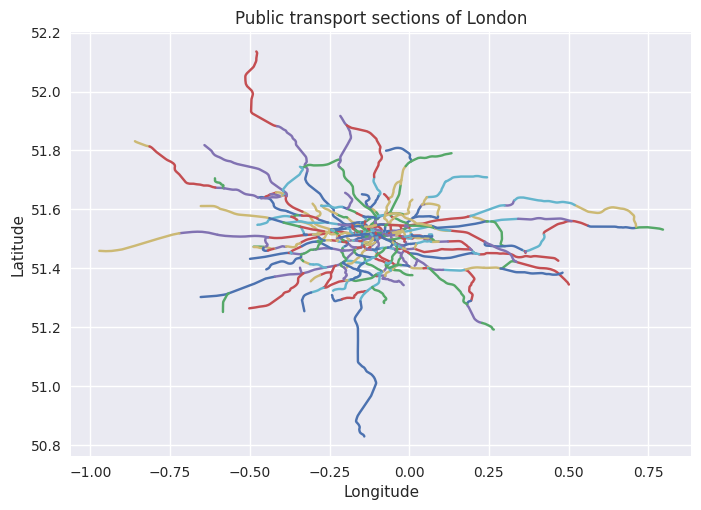
draw_sections('New York')