8. Kalenderdaten und Zeitreihen#
pandas unterstützt Kalenderdaten und Uhrzeiten als eigenen Datentyp. Dies bringt eine Reihe von Vorteilen und erweiterten Funktionalitäten gegenüber der Speicherung als String oder Behandlung als reinen Zahlenwert (auch wenn dies die Repräsentation im Speicher darstellt)):
Sortierung: nach Zeitstempeln kann von ältesten zu neuesten oder andersrum sortiert werden ohne auf eine entsprechende String-Repräsentation angewiesen zu sein (Stichworte: Reihenfolge und Vollständigkeit der Zeit- und Datumselemente, sowie führende Nullen)
Selektion: es kann z.B. auf alle Zeitstempel zugegriffen werden, die an einem bestimmten Tag oder in einem Monat sind.
Extraktion: es können auf Eigenschaften des Zeitstempels zugegriffen werden, z.B. auf den Wochentag oder die Minutenangabe
Resampling: wenn der Index aus Zeitstempeln besteht, dann kann mit der resample-Methode die Auflösung geändert werden, z.B. 1 Eintrag je Stunde oder Sekunde. Beim Sampling auf eine gröbere Auflösung (z.B. Tag zu Monat) werden die Werte aggregiert, beim Sampling auf eine feinere Auflösung (z.B. Stunde auf Minute) können die Daten interpoliert oder freigelassen werden
Generierung: es können bequem Zeitreihen generiert werden, wie z.B. alle Quartale der letzten und nächsten 3 Jahre
Timedelta: es können Differenzen zwischen Zeitstempeln erzeugt werden und automatisch in verschiedene Einheiten (z.B. Sekunden, Stunden, Tage) umgerechnet werden.
Einen Überblick über die weitere Möglichkeiten und deren Anwendung gibt der pandas User Guide zu Time Series und zu Time Deltas.
Die Übungen und Beispiele basieren auf Daten über weltweite Systeme des öffentlichen Nahverkehrs von https://www.citylines.co
8.1. Konvertierung in Zeitstempel#
Wenn wir Daten auslesen sind Kalenderdaten/Zeitstempel oftmals in einer String-Repräsentation vorhanden. Der erste Schritt ist eine Konvertierung in den entsprechenden Datentyp.
Im Folgenden verwenden wir die Zuordnungsdatei von Sektionen zu Linien, da diese Zeitstempel enthält. Die Zeitstempel created_at und updated_at beziehen sich auf die Bearbeitung der Tabelleneinträge. Unsere Analyse in diesem Kapitel bezieht sich somit mehr auf den Datensatz und wie (bzw. eher wann) er erstellt wurde als inhaltlich auf die Städte und Liniennetze.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# Cached version of https://data.heroku.com/dataclips/egetzfbhwqhqjbpedplrgppjlerc.csv
# Datum: 19.07.2021
section_lines = pd.read_csv("data/section_lines.csv", index_col='id')
section_lines.head()
| section_id | line_id | created_at | updated_at | city_id | fromyear | toyear | line_group | |
|---|---|---|---|---|---|---|---|---|
| id | ||||||||
| 2494 | 1278 | 343 | 2017-11-21 00:00:00 | 2017-11-21 00:00:00 | 252 | NaN | NaN | 0 |
| 4124 | 4477 | 779 | 2017-11-21 00:09:55.135507 | 2017-11-21 00:09:55.135507 | 63 | NaN | NaN | 0 |
| 2495 | 21 | 9 | 2017-11-21 00:00:00 | 2017-11-21 00:00:00 | 1 | NaN | NaN | 0 |
| 2496 | 940 | 228 | 2017-11-21 00:00:00 | 2017-11-21 00:00:00 | 79 | NaN | NaN | 0 |
| 4129 | 4478 | 793 | 2017-11-21 17:44:39.765832 | 2017-11-21 17:44:39.765832 | 48 | NaN | NaN | 0 |
section_lines.dtypes
section_id int64
line_id int64
created_at object
updated_at object
city_id int64
fromyear float64
toyear float64
line_group int64
dtype: object
Wie wir sehen wurden sowohl created_at als auch updated_at als Strings (Datentyp object) importiert. In unserem Fall entsprechen die Strings dem Standardformat: Einheiten werden mit Jahr startend und Sekunde ended immer kleiner, es werden - als Datumstrennzeichen, : als Zeitrennzeichen verwendet. Dennoch ist es immer ratsam as Format explizit anzugeben (Parameter format). Hier ist ein weiterer Parameter notwendig exact=False, da einige Daten noch zusätzlich Nanosekunden enthalten und somit nicht exakt auf das Format passen. Wir verwenden die Konvertierungsfunktion pd.to_datetime:
section_lines['created_at'] = pd.to_datetime(section_lines['created_at'], format='%Y-%m-%d %H:%M:%S', exact=False)
section_lines['updated_at'] = pd.to_datetime(section_lines['updated_at'], format='%Y-%m-%d %H:%M:%S', exact=False)
section_lines.dtypes
section_id int64
line_id int64
created_at datetime64[ns]
updated_at datetime64[ns]
city_id int64
fromyear float64
toyear float64
line_group int64
dtype: object
Wir sehen den geänderten Datentyp. Oftmals ist es notwendig das Datenformat anzugeben, bzw. auch wenn es nicht notwendig ist, ist es hilfreich das Format anzugeben, um fehlerhafte Daten zu erkennen. Die Doku über die Parameter findet sich in der API Referenz und die Beschreibung der zu nutzenden Format-Strings in der Python-Doku.
Nun können wir über den Namespace dt einer Zeitstempel-Series auf weitere Funktionen zugreifen, z.B. die Formatierung als Datum in deutschem Format ohne Uhrzeit:
section_lines['created_at'].dt.strftime("%d.%m.%Y")
id
2494 21.11.2017
4124 21.11.2017
2495 21.11.2017
2496 21.11.2017
4129 21.11.2017
...
20585 10.07.2021
20586 10.07.2021
20587 10.07.2021
20588 11.07.2021
20589 17.07.2021
Name: created_at, Length: 16303, dtype: object
8.2. Eigenschaften von Zeitstempeln#
Dass absolute Datum oder die absolute Uhrzeit von Ereignissen sind häufig uninteressant, da sie jeweils nur einzeln vorkommen und somit keine Muster erkennbar sind. Stattdessen interessieren uns wiederkehrende Eigenschaften wie z.B. die Stunde der Uhrzeit. Im Folgenden erstellen wir eine Spalte für die Stunde, um zu sehen zu welchen Tageszeiten am meisten am Datensatz gearbeitet wurde.
# Extraktion der Stunde per dt-Accessor aus der Series
# Abspeichern in neuer Spalte
section_lines['hour'] = section_lines['created_at'].dt.hour
# Gruppierung auf der neuen Spalte je Stunde und zählen der Einträge (size)
section_lines.groupby('hour').size().plot()
plt.show()
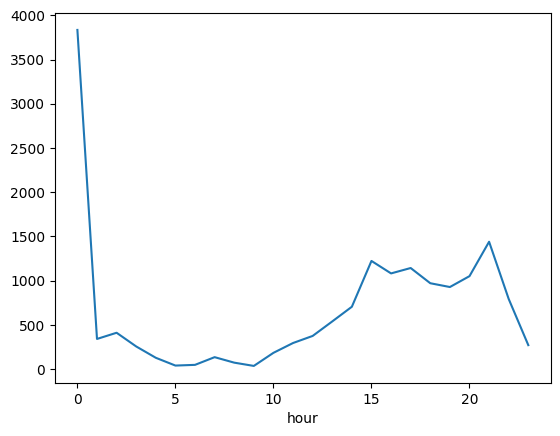
Wie wir sehen wurde der größte Teil der Dateneinträge um 0 Uhr gemacht. Wir wollen uns diese Einträge genauer anschauen. Dazu filtern wir die Tabelle auf alle Einträge der Stunde 0 und schauen, dann an welchen Tagen wir wie viele dieser Einträge haben.
section_lines.loc[section_lines['hour'] == 0, 'created_at'].dt.strftime('%Y-%m-%d').value_counts().head(10)
2017-11-21 3577
2021-01-05 41
2018-02-04 38
2020-12-28 25
2020-11-04 18
2021-02-14 18
2021-01-27 14
2021-02-11 14
2021-03-15 8
2020-04-05 7
Name: created_at, dtype: int64
Es fällt auf, dass die meisten dieser Einträge auf einen einzelnen Tag fallen. Unsere Hypothese ist, dass es sich hierbei um die initiale Erstellung/den initialen Import des Datensatz handelt. Wir überprüfen dies indem wir dass Startdatum des Datensatzes berechnen und können bestätigen, dass diese Änderungen tatsächlich in der Stunde 0 des ersten Tages des Datensatzes fallen:
section_lines['created_at'].min()
Timestamp('2017-11-21 00:00:00')
Da wir an den fortlaufenden Aktivitäten interessiert sind filtern wir alle Aktivitäten des ersten Tag heraus. Dabei können wir mit <, > arbeiten und gegen einen Datums-String vergleichen.
section_lines = section_lines[section_lines["created_at"] >= '2017-11-22'].copy()
Nun können wir erneut die Analyse nach Uhrzeit machen - dieses Mal als Bar-Chart:
creates_per_hour = section_lines.groupby('hour').size()
plt.bar(creates_per_hour.index, creates_per_hour.values)
plt.xticks(ticks=creates_per_hour.index, labels=creates_per_hour.index)
plt.show()
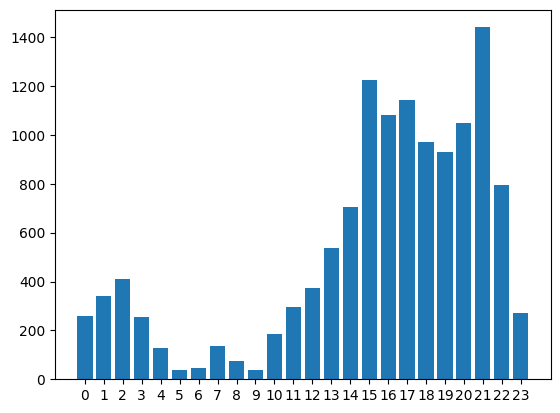
Nun sehen wir eine Häufung am Nachmittag und in den Abendstunden. Vermutlich wird der Datensatz also in der Freizeit erstellt. Um dies weiter zu untersuchen betrachten die die Datensätze pro Wochentag:
section_lines['weekday'] = section_lines['created_at'].dt.day_name()
creates_per_weekday = section_lines.groupby('weekday').size()
plt.bar(x=creates_per_weekday.index, height=creates_per_weekday.values)
plt.show()
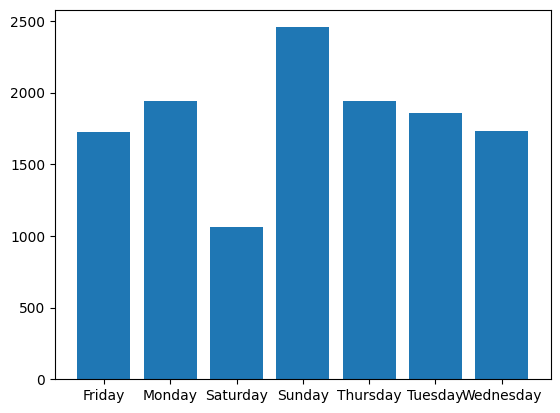
8.3. Zeitreihen erzeugen#
Das vorherige Chart zeigt zwar die Aktivitäten nach Wochentag - diese sind jedoch Alphabetisch statt nach ihrer Reihenfolge in der Woche sortiert. Dies ändern wir in dem den Datentyp auf eine sortierte Kategorie ändern. Um diesen Typ und die korrekte Reihenfolge zu erstellen, könnten wir einfach “Monday” bis “Sunday” in der richtigen Reihenfolge in eine Liste tippen. Wir wählen stattdessen einen anderen Weg:
Wir erstellen mit
pd.date_rangeeine Zeitreihe von 7 aneinanderfolgenden Tagen - somit ist die Abdeckung aller Wochentage sichergestelltWir fügen Spalten für
weekday(Durchnummerierung der Wochentage von 0 - Montag bis 6 - Sonntag) unddayname(Strings der Namen der Wochentage)Wir sortieren nach
weekdayund haben dann in der Spaltedaynamedie Wochentage in der korrekten Reihenfolge:
# Erzeuge 7 aufeinanderfolgende Tage (genaues Datum eigentlich egal)
from datetime import date
oneweek = pd.DataFrame(index=pd.date_range(start=date(2021,1,1),periods=7, freq='D'))
oneweek['weekday'] = oneweek.index.weekday
oneweek['dayname'] = oneweek.index.day_name()
oneweek.sort_values('weekday', inplace=True)
ordered_daynames = oneweek['dayname'].values
ordered_daynames
from pandas.api.types import CategoricalDtype
dayname_type = CategoricalDtype(categories=ordered_daynames, ordered=True)
dayname_type
CategoricalDtype(categories=['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday',
'Saturday', 'Sunday'],
, ordered=True)
Nun können wir den Datentyp der ‘weekday’-Spalte auf die Kategorie setzen und die Reihenfolge wird bei zukünftigen Analysen berücksichtigt:
section_lines['weekday'] = section_lines['weekday'].astype(dayname_type)
creates_per_weekday = section_lines[section_lines['created_at'] >= '2017-11-22'].groupby('weekday').size()
plt.bar(x=creates_per_weekday.index, height=creates_per_weekday.values)
plt.show()
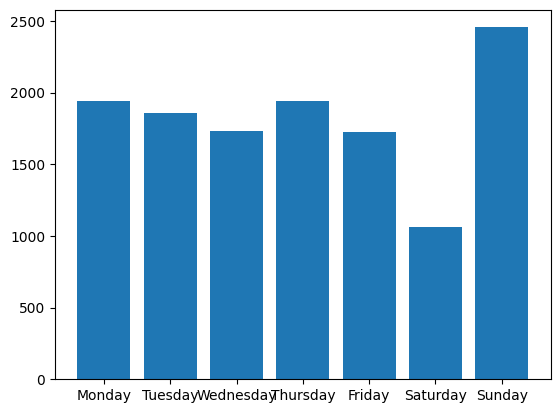
8.4. Visualisierung nach zwei Dimensionen: Heatmap#
Nun interessiert uns im nächsten Schritt die Kombination aus Wochentag und Uhrzeit. Die Anzahl der Änderungen je Kombination könnten wir nun in 3D anzeigen - solche Charts sind jedoch häufig schwer zu greifen. Stattdessen bietet sich eine Heatmap an - hier wird die dritte Dimension (die Hitze oder Intensität) als Farbe auf einer Farbskala repräsentiert. Seaborn bietet eine praktische Funktion heatmap an, die die Erstellung für uns übernimmt. Als Voraussetzung sollte der Index des DataFrames den gewünschten Zeilten der Heatmap entsprechend und das gleiche gilt für die Spalten des DataFrames und der Heatmap. Dies erreichen wir durch ein Pivotieren des Datensatzes:
weekday_hours = section_lines.pivot_table(index='hour', columns='weekday',
values='line_id', aggfunc='count', fill_value=0)
weekday_hours.head()
| weekday | Monday | Tuesday | Wednesday | Thursday | Friday | Saturday | Sunday |
|---|---|---|---|---|---|---|---|
| hour | |||||||
| 0 | 38 | 54 | 45 | 24 | 15 | 3 | 79 |
| 1 | 57 | 55 | 66 | 102 | 15 | 23 | 23 |
| 2 | 20 | 168 | 44 | 49 | 49 | 64 | 17 |
| 3 | 52 | 47 | 48 | 57 | 21 | 12 | 19 |
| 4 | 17 | 20 | 34 | 9 | 20 | 2 | 26 |
# Erstellen der Heatmap
plt.figure(figsize=(10,6))
sns.heatmap(weekday_hours, annot=True, fmt="d", linewidths=.5,cmap="YlGnBu")
plt.show()
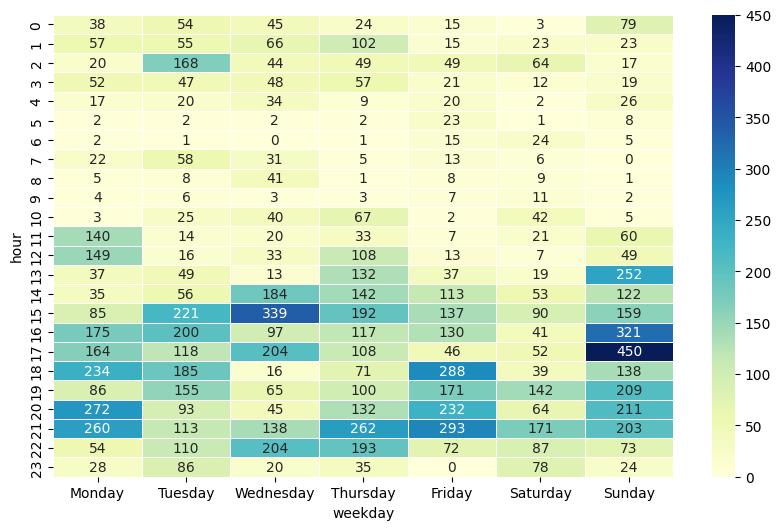
Im vorherigen Schaubild können wir Muster der Benutzer ableiten, wann sie am meisten am am Datensatz gearbeitet haben. Wir können eine Heatmap auch nutzen, um den zeitlichen Verlauf wann wie viele Daten hinzugekommen sind darzustellen. Erstellen Sie hierzu eine Heatmap mit den Jahren als Zeilen und den Monaten als Spalten.
#
Show code cell content
year_months = section_lines.pivot_table(index=section_lines['created_at'].dt.year,
columns=section_lines['created_at'].dt.month,
values='line_id', aggfunc='count', fill_value=0)
plt.figure(figsize=(10,6))
sns.heatmap(year_months, annot=True, fmt="d", linewidths=.5,cmap="YlGnBu")
plt.show()
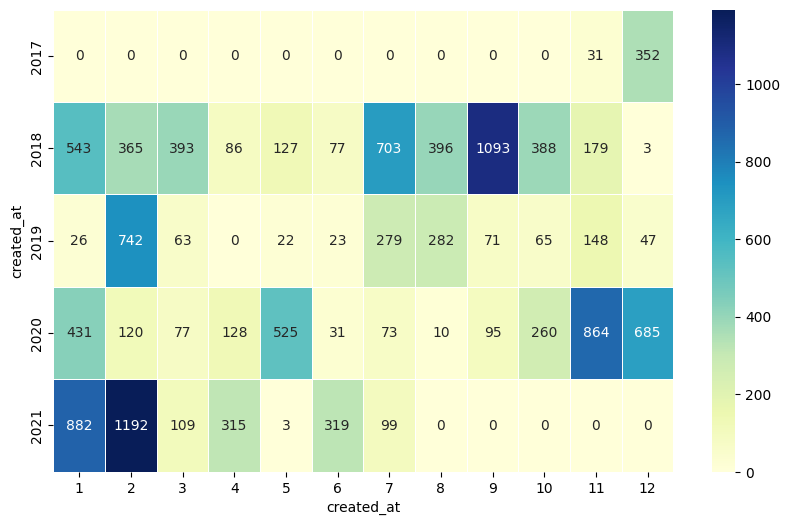
8.5. Zeitdifferenzen#
Neben einzelnen Zeitpunkten ist häufig auch der Abstand zwischen verschiedenen Zeitpunkten von Interesse. Dazu gibt es [pd.Timedelta]https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.Timedelta.html(). Eine Timedelta entsteht z.B. automatisch wenn zwei Zeitreihen voneinander abgezogen werden:
# Berechne Zeitraum zwischen Erstellung und lezten Update - Rundung auf ganze Tage
delta = (section_lines['updated_at'] - section_lines['created_at']).round('D')
# Zeige die Einträge die einen Abstand von mindestens 1000 Tagen haben
delta[delta >= '1000 days']
id
4389 1212 days
4394 1212 days
dtype: timedelta64[ns]
Bei Betrachtung der Werteverteilung fällt auf, dass die meisten Datenpunkte einen Abstand von 0 Tagen haben, d.h. sie wurden wohl noch nie geupdated:
delta.value_counts()
0 days 12223
1 days 66
221 days 50
2 days 33
20 days 22
...
154 days 1
93 days 1
62 days 1
61 days 1
273 days 1
Length: 80, dtype: int64
Wir plotten nun die Werteverteilung nur der Datensätze, die überhaupt ein Update erfahren haben und sehen eine stark abflachende Kurve. Wir interpretieren dies, dass je mehr Zeit vergeht umso unwahrscheinlicher wird ein Update:
delta[delta >= pd.Timedelta(1, 'D')].value_counts().plot()
plt.show()
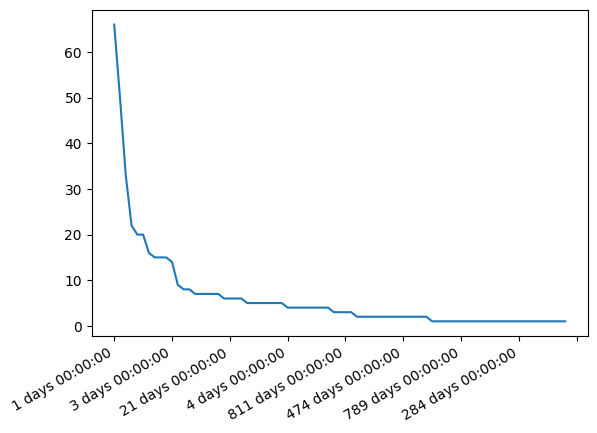
Berechnen Sie den maximalen Abstand in dem nichts Neues im Datensatz erstellt wurde. Gehen Sie wie folgt vor:
- Sortieren Sie nach created_at
- Berechnen Sie den Zeitabstand zwischen den einzelnen Daten, nutzen Sie hierfür die diff-Methode
- Geben Sie den größten Zeitabstand aus
#
Show code cell content
section_lines.sort_values('created_at')['created_at'].diff().max()
Timedelta('38 days 15:09:09.868319')
8.6. Zeitstempel als Index#
Wenn wir einen Zeitstempel als Index setzen, können wir den Datensatz “resamplen”. Dabei wird die Zeitreihe von einer Frequenz auf eine andere umgerechnet. Dabei werden unregelmäßige Zeitstempel (z.B. ein Eintrag diesen Montag, dann zwei Einträge am Mittwoch um 11 und 13 Uhr) auf Intervalle fixe Abstände gebracht (z.B. ein Eintrag jeden Tag oder jede Stunde). Beim Sampling auf eine gröbere Auflösung (z.B. Tag zu Monat) werden die Werte aggregiert, beim Sampling auf eine feinere Auflösung (z.B. Stunde auf Minute) können die Daten interpoliert oder freigelassen werden
Im Folgenden gruppieren wir zuerst auf created_at und zählen die Einträge. created_at wird dabei automatisch als Index gesetzt:
create_events = section_lines.groupby('created_at').agg({'line_id': 'count'})
create_events.max()
line_id 1
dtype: int64
Anhand des Max-Wertes sehen wir, dass zu jeden Zeitpunkt immer nur genau ein Update erfolgt. Das klingt plausibel, wenn wir beachten, dass wir den initialen Import ausgefilter haben und ansonsten die Zeitstempel auf Nanosekunden-Ebene sind. Das entsprechende Chart ist nicht sondern aussagekräftig:
create_events.plot()
plt.show()
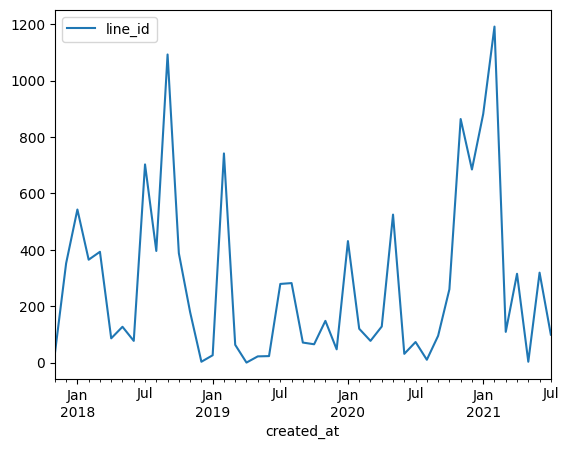
Wenn wir stattdessen ein resampling auf Monatsebene (Parameter M) machen erhalten wir eine interessantere Graphik. Dabei werden mit Hilfe von sum die Änderungen aufaddiert:
create_events.resample('M').sum().plot()
plt.show()
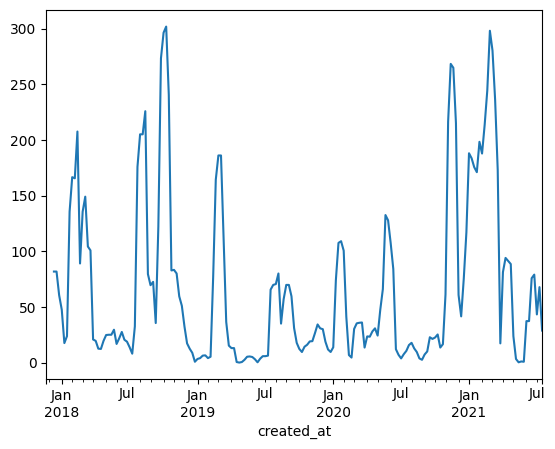
Wir können z.B. auch auf Wochenebene (Parameter W) resampeln und dann einen rollierenden (Methode rolling) Durchschnitt (Methode mean auf dem Ergebnis von rolling) über die letzten 4 Wochen bilden. Dabei erzeugen wir einen Datenpunkt pro Woche - statt wie zuvor pro Monat. Die aufgetragene Zahl bezieht sich immer auf diese Woche und die drei vorhergehenden:
# Immer noch 4 Wochen (ca. 1 Monat) aber rollierend
create_events.resample('W').size().rolling(4).mean().plot()
plt.show()
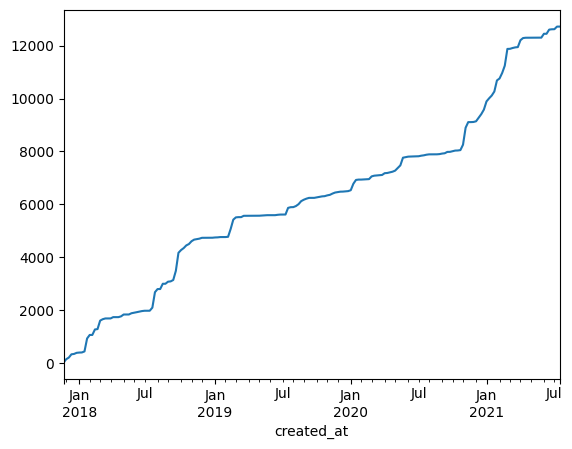
Über die Rollierung kann eine Glättung der Zahlen erreich werden. Eine andere Möglichkeit ist die Größe über die Zeit darzustellen. Im Folgenden ist das als kumulative Summe der neuen Einträge gelöst:
create_events.resample('W').size().cumsum().plot()
plt.show()