1. Evaluierung und Interpretation#
Sie haben in den Einheiten zur Datenmodellieren schon einige wichtige Punkte zum Thema “Evaluierung” gesehen: Die geeigneten Evaluationsmaße und ihre Interpretation, oder die methodisch saubere Trennung von Parameter- und Modellauswahl gegenüber den ungesehenen Testdaten, die die Generalisierbarkeit der Ergebnisse garantiert.
In diesem Abschnitt liegt der Fokus darauf, Ihre Ergebnisse einzuordnen und zu erklären (also auf Eigenschaften der Daten zurückzuführen). Dieser Schritt kommt beim reinen Machine Learning oft zu kurz, bringt aber die eigentlichen Einsichten.
Wir behandeln die folgenden Aspekte:
Evaluierung: Wie gut ist das Modell im Vergleich?
zu einem anderen Modell: Baselines
zu sich selbst über die Zeit: Über- und Unteranpassung (overfitting/underfitting) mit Hilfe von Lernkurven prüfen
Interpretation: Welche Attribute sind (für welchen Teil der Daten) besonders wichtig?
2. Evaluierung#
2.1. 1. Baselines#
Die Evaluationsergebnisse Ihres Modells sind für sich genommen schwer zu interpretieren: Ist ein F-Wert von 0.8 gut oder schlecht? Um dies besser einschätzen zu können, formulieren oder trainieren wir Vergleichsmodelle, sogenannte Baselines, bei denen wir davon ausgehen, dass unser Modell sie schlagen sollte (z.B. weil es mächtiger ist, also mehr Parameter besitzt, um die Eigenschaften der Daten abzubilden).
1.1 Frequenzbaseline (Klassifikation)#
Eine sehr naive Baseline, die aber bei stark unausgewogenen Datensätzen dennoch hoch informativ ist, ist die Frequenzbaseline (bei Klassifikationsaufgaben). Sie wird berechnet, indem allen Datenpunkten die häufigste Klasse zugewiesen wird. Bei einem binären Klassifikationsproblem mit einer sehr häufigen Klasse kann die Frequenzbaseline bereits sehr hoch liegen - gegen eine Frequenzbaseline von F=0.9 sieht F=0.8 des trainierten Systems vielleicht gar nicht so eindrucksvoll aus. Im Vergleich der Konfusionsmatritzen mag das wieder anders aussehen; hier wird beim vermeintlich schlechteren System der kleineren Klasse sicher mehr korrekt zugewiesen als bei der Frequenzbaseline.
Wir verwenden in diesem Abschnitt unseren Ausschnitt aus den 20 Newsgroups-Daten als Beispiel.
# Imports
from sklearn.datasets import fetch_20newsgroups
from sklearn.model_selection import train_test_split
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import f1_score
from sklearn.pipeline import Pipeline
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.feature_selection import SelectFromModel
from sklearn.svm import LinearSVC, SVC
from sklearn.pipeline import Pipeline
from sklearn.naive_bayes import GaussianNB
from sklearn.preprocessing import FunctionTransformer
from sklearn.metrics import classification_report
# 20 Newsgroups-Daten holen und in Train - Dev - Test aufteilen
categories = [
'alt.atheism',
'talk.religion.misc',
'comp.graphics',
'sci.space',
]
remove = ('headers', 'footers', 'quotes')
data_train = fetch_20newsgroups(subset='train', categories=categories,
shuffle=True, random_state=42,
remove=remove)
data_test = fetch_20newsgroups(subset='test', categories=categories,
shuffle=True, random_state=42,
remove=remove)
# Übersicht über Klassen in den Trainingsdaten
print("Gesamtzahl Datenpunkte Training: ", len(y_train))
for i in range(0,4):
print("Anzahl Kategorie", str(i), list(y_train).count(i))
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
/tmp/ipykernel_636/1723242245.py in <module>
1 # Übersicht über Klassen in den Trainingsdaten
2
----> 3 print("Gesamtzahl Datenpunkte Training: ", len(y_train))
4
5 for i in range(0,4):
NameError: name 'y_train' is not defined
Die häufigste Klasse ist also 2.
# Und die Entwicklungsdaten?
print("Gesamtzahl Datenpunkte Dev: ", len(y_dev))
for i in range(0,4):
print("Anzahl Kategorie", str(i), list(y_dev).count(i))
Gesamtzahl Datenpunkte Dev: 407
Anzahl Kategorie 0 96
Anzahl Kategorie 1 117
Anzahl Kategorie 2 119
Anzahl Kategorie 3 75
Aufgabe: Berechnen Sie mit Hilfe von sklearn.metrics.f1_score(average=’weighted’) das Ergebnis, wenn wir für die Testdaten immer ‘2’ vorhersagen.
# Lösung:
# Vorhersage-Array bauen: Für jedes Element der Entwicklungsdaten Klasse '2' vorhersagen
pred = np.full(len(y_dev),2)
Aufgabe: Das Ergebnis ist ziemlich niedrig - warum?
1.2 Mittelwertsbaseline (Regression)#
Die entsprechende Baseline für eine Regressionsaufgabe ist, auf den Testdaten immer den Mittelwert der Trainingsdaten vorherzusagen. Auch hier hängt die Aussagekraft der Baseline von den Daten ab: Variieren die Zielwerte sehr stark, ist die Mittelwertvorhersage natürlich ähnlich schlecht wie die Frequenzbaseline im Beispiel für die Klassifikation.
Es folgt ein Beispiel mit den California-Housing-Daten (s. Kap. “Regression”, Aufgabe).
# Imports
from sklearn.datasets import fetch_california_housing
import sklearn.ensemble
import numpy as np
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
from math import sqrt
# Daten laden
data = fetch_california_housing(as_frame=True)
# Daten aufteilen
b_X_train, b_X_test, b_y_train, b_y_test = train_test_split(data.data, data.target, test_size=.2)
# Modell trainieren
clf = LinearRegression()
clf.fit(b_X_train, b_y_train)
# Modell evaluieren
test_predict = clf.predict(b_X_test)
print("RMSE der Modellvorhersagen: ", sqrt(mean_squared_error(b_y_test, test_predict)))
# Mittelwertsvorhersage: Vorhersage ist ein Array in Länge der Testdaten, der an jeder Position den
# Mittelwert der Zieldaten aus dem Trainingsset enthält
test_predict_mean = np.full(len(b_y_test),b_y_train.mean())
print("RMSE der Mittelwertsbaseline: ", sqrt(mean_squared_error(b_y_test, test_predict_mean)))
RMSE der Modellvorhersagen: 0.7232561838693107
RMSE der Mittelwertsbaseline: 1.1628367462545748
Wir sehen auch hier, dass das trainierte Modell deutlich besser ist als die naive Baseline.
1.3 Einfaches Vergleichsmodell#
Wir können auch ein bewusst einfaches Modell zum Vergleich trainieren (z.B. den Naive Bayes-Lerner für die Klassifikation oder ein einfaches lineares Modell für die Regression). Das haben wir beim Kapitel über Regression bereits getan: Unser bewusst simples Modell mit nur einem (theoretisch motivierten) Feature stellte eine Art untere Grenze für die weiteren Modellierungsschritte dar.
Hier ein Beispiel mit einem einfachen Naive Bayes-Klassifikator für unsere 20 Newsgroups-Daten.
# Aus Kap. "Klassifikation" die besten Settings für die Pipeline abschreiben;
# Der Lerner soll Naive Bayes sein; dieser Lerner akzeptiert keine spärlich besetzten Vektoren,
# daher ein zusätzlicher Transformationsschritt
baseline_pipeline = Pipeline(steps=[('vectorizer', TfidfVectorizer(max_df=0.5)),
('feature_selection',
SelectFromModel(estimator=LinearSVC(dual=False,
penalty='l1'), threshold='mean')),
('densify_vectors',FunctionTransformer(lambda x: x.toarray(), accept_sparse=True)),
('classifier', GaussianNB())])
baseline_pipeline.fit(data_train['data'], data_train['target'])
# Lerner auf den Testdaten evaluieren
dev_labels = baseline_pipeline.predict(data_test['data'])
print(classification_report(data_test['target'], dev_labels))
precision recall f1-score support
0 0.66 0.50 0.57 319
1 0.68 0.89 0.77 389
2 0.82 0.66 0.73 394
3 0.54 0.61 0.57 251
accuracy 0.68 1353
macro avg 0.68 0.67 0.66 1353
weighted avg 0.69 0.68 0.68 1353
Gemessen an dieser Baseline sind unsere Ergebnisse mit dem SVM (per crossvalidation auf den Trainingsdaten erhoben) ganz gut: weighted average F-Score war dort 0.79.
Der SVM schlägt also die (in diesem Fall ziemlich niedrige) Frequenzbaseline deutlich und ist auch besser als ein bewusst einfach gehaltenes Modell: Im Vergleich mit anderen Modellen schneidet er gut ab.
Dennoch sind Precision und Recall noch nicht (sehr) nahe an 1. Sehen wir also Underfitting, und das das Modell könnte noch besser werden? Im nächsten Schritt (Abschnitt 2) betrachten wir, wie er sich im Lernprozess verhält, vergleichen das Modell also quasi gegen sich selber.
2.2. 2. Over-/Underfitting mit Lernkurven prüfen#
Wenn wir ein Modell trainiert haben, möchten wir sicher sein, dass es 1. bestmöglich funktioniert und 2. generalisiert, also auf ungesehenen Daten vergleichbare Performanz zeigt.
Der erste Wurf beim Training eines Modells ist meistens noch suboptimal: Das Modell hat nicht alle generalisierbaren Eigenschaften der Daten gelernt (dies nennt sich underfitting). Je länger Sie auf den Trainings- und Entwicklungsdaten arbeiten, desto besser wird Ihr Modell - zunächst bildet es die generalisierbaren Eigenschaften der Daten besser ab, aber ab einem bestimmten Punkt lernt es, die nicht-generalisierbaren Details abzubilden (overfitting) und wird dadurch auf ungesehenen Daten schlechter.
Sie suchen also den Punkt, an dem das Modell genau “die richtigen” Eigenschaften der Daten gelernt hat. Dafür dürfen Sie aber nicht die ungesehenen Testdaten zu Hilfe nehmen, denn sonst riskieren Sie die implizite Überanpassung an die Testdaten, die dann nicht mehr ungesehen sind und die Generalisierbarkeit der Ergebnisse nicht mehr garantieren können.
Wir sind also auf Trainings- und Entwicklungsdaten angewiesen und behelfen uns damit, anzuschauen, wie das Modell auf diesen beiden Datensätzen funktioniert. Natürlich wird die Performanz auf den Trainingsdaten “zu gut” sein - diese sind ja bekannt… Aber so haben wir zwei Datensätze, auf denen wir evaluieren können, ohne die Testdaten anzuschauen.
Als zweiten Trick schauen wir uns an, wie das Modell auf mehr und mehr Trainingsdaten reagiert. Wir teilen dafür die Trainingsdaten in kleine Abschnitte und plotten die Modellperformanz mit zunehmender Trainingsdatenmenge. Anfangs wird die Lernkurve des Modells für beide Datensätze relativ steil ansteigen, weil es mehr und mehr verwertbare Information aus immer größeren Tranchen der Entwicklungsdaten ziehen kann; irgendwann flacht die Kurve aber möglicherweise ab, falls die übrigen Trainingsdaten keine neue Information mehr liefern.
Liegen die Maximalwerte nah beieinander und der Maximalwert ist auch noch relativ niedrig (im Vergleich zu den Baselines), liegt wahrscheinlich Underfitting vor: Das Modell ist nicht mächtig genug, um die weiteren Trainingsdaten effizient zu nutzen.
Ein Modell, das auf den Trainingsdaten wenig Fehler macht, aber auf den Entwicklungsdaten konsistent deutlich schlechter abschneidet, zeigt eher Overfitting; es ist offenbar mächtig genug, um über die relevanten Dateneigenschaften hinaus noch weitere Details zu lernen und würde von mehr Trainingsdaten profitieren.
Wir probieren die Lernkurvenanalyse für den SVM-Klassifizierer aus.
# Lernkurve erstellen (Code angepasst von Géron (2019), Kap. 4):
# Jeweils in Schritten von 100 Trainingsbeispielen iterieren;
# bei jedem Durchlauf trainieren und auf Trainings- und Entwicklungsdaten
# testen
# Achtung hierbei: Trainingsdaten müssen randomisiert sein, damit
# nicht zunächst nur eine Klasse im Training präsentiert wird.
# (Unsere Daten in den nächsten Schritten sind randomisiert!)
# Ergebnisse (F-Scores) plotten.
def plot_learning_curves(model, X_train,y_train, X_dev, y_dev):
train_fs, dev_fs = [], []
for m in range(100, X_train.shape[0],100):
model.fit(X_train[:m], y_train[:m])
y_train_predict = model.predict(X_train[:m])
y_dev_predict = model.predict(X_dev)
train_fs.append(f1_score(y_train[:m], y_train_predict,average='weighted'))
dev_fs.append(f1_score(y_dev, y_dev_predict, average='weighted'))
plt.plot(train_fs, "r-+", linewidth=2, label="train")
plt.plot(dev_fs, "b-", linewidth=3, label="dev")
plt.legend()
plt.xlabel('Index der Trainingsiteration')
plt.ylabel('F-Score des Lerners')
Wir bereiten aus Effizienzgründen die Daten auf, bevor wir die Lernkurve plotten. Die ursprünglichen Textdaten werden wie im Kap. “Klassifikation” vektorisiert, die Dimensionen dabei per TF-IDF ausgewählt. Anschließend werden die aussagekräftigsten Dimensionen ausgewählt.
Aufgabe: Gibt es auch Argumente dafür, die Datenaufbereitung bei jedem Schritt (also für jeden neu erstellten Teildatensatz) neu durchzuführen?
# Trainings- und Entwicklungsdaten vorbereiten: Aus Texten Vektoren erstellen und die besten Features auswählen
X_train, X_dev, y_train, y_dev = train_test_split(data_train['data'], data_train['target'],
test_size=0.2,
random_state=42,
stratify=data_train['target'])
vectorizer = TfidfVectorizer(max_df=0.5)
data_train_vectorized = vectorizer.fit_transform(X_train)
featureSelector = SelectFromModel(estimator=LinearSVC(dual=False,penalty='l1'))
data_train_optimal = featureSelector.fit_transform(data_train_vectorized, y_train)
data_dev_vectorized = vectorizer.transform(X_dev)
data_dev_optimal = featureSelector.transform(data_dev_vectorized)
# Lerner vorbereiten: SVM
svm = SVC()
# Lernkurve plotten - läuft eine Weile!
plot_learning_curves(svm, data_train_optimal, y_train, data_dev_optimal, y_dev)
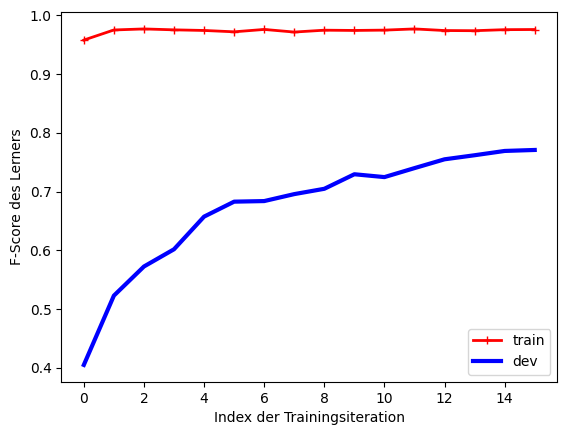
Aufgabe: Was ziehen Sie aus diesem Plot für Schlüsse? Haben wir eher Over- oder Underfitting? Wie könnten wir gegensteuern?
3. Interpretation#
Wir haben bislang gesehen, wie wir die Performanz eines Lerners absolut (gegen Baselines) und relativ (in Bezug auf sein eigenes Lernverhalten) einschätzen können. Damit bekommen wir einen guten Eindruck vom Verbesserungspotential des gewählten Ansatzes auf den zur Verfügung stehenden Daten.
Vom Standpunkt der Datenanalyse her interessiert uns aber auch, welche Eigenschaften der Daten (also welche Features) besonders relevant für den Lerner sind. Dies haben wir bei der linearen Regression explizit evaluiert, und entsprechend können Sie auch die gelernten Modelle von transparenten Algorithmen wie Entscheidungsbäumen direkt interpretieren.
Aber auch für Algorithmen, deren Modelle nicht menschenlesbar sind, gibt es Verfahren, die das Lernerverhalten erklären sollen. Diese können auch für transparente Algorithmen zusätzlich eingesetzt werden!
Ein Ansatz, den wir aus Aufwandsgründen nicht selber ausprobieren werden, ist das sog. Adversarial Testing (also etwa “feindseliges Testen”). Hier überlegt man sich im Voraus Testfälle, für die man das Verhalten des Lerners genauer prüfen möchte. Das können Fälle aus der Grauzone zwischen zwei Kategorien sein, oder zu erwartende fehlerhafte Eingaben durch Endnutzer. Dann wird das trainierte Modell auf (größeren Mengen) solcher Testdaten evaluiert. Dadurch hat man gezielt Einblick in relevante Teilbereiche der Daten, die im Testdatensatz ggf. unterrepräsentiert sind.
Wir werden stattdessen einen anderen Ansatz ausprobieren: LIME (“Local Interpretable Model-agnostic Explanations”, Paper). Dieser hat das Ziel, für jede Testinstanz individuell zu begründen, warum der trainierte Lerner seine Vorhersage gemacht hat. Dies ist natürlich hoch relevant, wenn Sie den Endnutzer:innen die Möglichkeit geben möchten, Modellvorhersagen selbst zu interpretieren.
Ein Beispiel: Hautärzt:innen verwenden oft automatisierte Systeme, um Muttermale mit Hautkrebspotential zu entdecken. Eine Systemausgabe, die die Bewertung als “riskant” oder “nicht riskant” begründet, ermöglicht den Ärzt:innen, ihre eigene Einschätzung und die des Systems zu gewichten und vielleicht doch zu einer abweichenden Interpretation zu gelangen, statt blind dem System zu folgen.
Ebenso ist in der DSGVO geregelt, dass Verbraucher:innen ein Recht darauf haben, dass ihnen Entscheidungen aufgrund eines Algorithmus erläutert werden; dann braucht man exakt solche Einzelfallbegründungen, wie LIME sie liefern kann.
LIME funktioniert folgendermaßen: Der Algorithmus geht davon aus, dass der zu testende Lerner eine Black Box ist. Wir kennen also nur seine Ausgabe als Reaktion auf die Eingabefeatures. Um zu verstehen, welche Eingabefeatures die Ausgabe besonders beeinflusst haben, trainieren wir jetzt einen transparenten Lerner darauf, die Ausgabe des Black Box-Lerners vorherzusagen. Der transparente Lerner wird uns dann sagen, welche Features besonders wichtig waren, um die Black Box möglichst gut zu imitieren.
Leider bleibt das Problem, dass der transparente Lerner (ein lineares Modell) ggf. nicht mächtig genug ist, um die Black Box korrekt zu emulieren (sonst hätte man ja wahrscheinlich gar nicht erst einen intransparenten Algorithmus gewählt…). Jetzt kommt der Namensbestandteil “Local” ins Spiel: Der Algorithmus bricht das Problem auf das Umfeld des aktuellen Testdatenpunkts herunter. Er ignoriert also große Teile der Trainingsdaten, die im Moment gar nicht relevant sind. Stattdessen simuliert er Instanzen, die sich in der Nähe des Testdatenpunkts befinden und lernt aus ihnen ein lokales Entscheidungsmodell, das dem Verhalten der Black Box an dieser Stelle entspricht. Für die Textklassifikation werden z.B. zufällig Wörter aus dem Text weggelassen, um die ähnlichen Dokumente zu generieren.
Wir probieren es aus… Wir folgen dem LIME-Tutorial für den Multiclass-Fall (also mehr als zwei Zielklassen). LIME ist auch im binären Klassifikationsfall und für Regressionsprobleme anwendbar; Tutorials dazu gibt es ebenfalls im verlinkten GitHub-Projekt.
3.1. Erklärungen für einzelne Instanzen#
Wir probieren es aus… Wir folgen dem LIME-Tutorial für den Multiclass-Fall (also mehr als zwei Zielklassen). LIME ist auch im binären Klassifikationsfall und für Regressionsprobleme anwendbar; Tutorials dazu gibt es ebenfalls im verlinkten GitHub-Projekt.
# Imports
from __future__ import print_function
import warnings
warnings.simplefilter(action='ignore', category=FutureWarning)
import lime
import sklearn
import numpy as np
import sklearn
import sklearn.ensemble
import sklearn.metrics
from sklearn.svm import SVC
from sklearn.pipeline import Pipeline
from lime import lime_text
from lime.lime_text import LimeTextExplainer
# Vorbereitung der Daten (sicherheitshalber noch einmal)
# Trainings- und Entwicklungsdaten aus 20 Newsgroups einlesen und aufteilen wie oben
# 20 Newsgroups-Daten holen und in Train - Dev - Test aufteilen
categories = [
'alt.atheism',
'talk.religion.misc',
'comp.graphics',
'sci.space',
]
remove = ('headers', 'footers', 'quotes')
data_train = fetch_20newsgroups(subset='train', categories=categories,
shuffle=True, random_state=42,
remove=remove)
data_test = fetch_20newsgroups(subset='test', categories=categories,
shuffle=True, random_state=42,
remove=remove)
X_train, X_dev, y_train, y_dev = train_test_split(data_train['data'], data_train['target'],
test_size=0.2,
random_state=42,
stratify=data_train['target'])
# Wir benennen die Klassen noch menschenlesbar:
class_names=['atheism','graphics','space','religion.misc']
# Pipeline für Datenvorverarbeitung und Training (wie in Kap. 2 "Klassifikation")
# Lerner: SVM wie oben, aber Ausgabe einer Wahrscheinlichkeitsverteilung über alle Klassen
c = Pipeline(steps=[('vectorizer', TfidfVectorizer(max_df=0.5)),
('feature_selection',
SelectFromModel(estimator=LinearSVC(dual=False,
penalty='l1'))),
('classifier', SVC(probability=True))])
# Pipeline trainieren
c.fit(X_train, y_train)
Pipeline(steps=[('vectorizer', TfidfVectorizer(max_df=0.5)),
('feature_selection',
SelectFromModel(estimator=LinearSVC(dual=False,
penalty='l1'))),
('classifier', SVC(probability=True))])In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Pipeline(steps=[('vectorizer', TfidfVectorizer(max_df=0.5)),
('feature_selection',
SelectFromModel(estimator=LinearSVC(dual=False,
penalty='l1'))),
('classifier', SVC(probability=True))])TfidfVectorizer(max_df=0.5)
SelectFromModel(estimator=LinearSVC(dual=False, penalty='l1'))
LinearSVC(dual=False, penalty='l1')
LinearSVC(dual=False, penalty='l1')
SVC(probability=True)
# Der Lerner gibt eine Wahrscheinlichkeitsverteilung über die verschiedenen Klassen aus:
print(c.predict_proba([X_dev[0]]).round(3))
[[0.561 0.163 0.119 0.156]]
# Explainer generieren
explainer = LimeTextExplainer(class_names=class_names)
# Erklärung für einen bestimmten Datenpunkt generieren: Index 42
# Es sollen für die beiden wahrscheinlichsten Klassen (top_labels=2)
# die jeweils 6 wichtigsten Features generiert werden (num_features=6)
idx = 1
exp = explainer.explain_instance(X_dev[idx], c.predict_proba, num_features=6, top_labels=2)
print('Document id: %d' % idx)
print('Predicted class:', class_names[c.predict([X_dev[idx]])[0]])
print('True class: %s' % class_names[y_dev[idx]])
Document id: 1
Predicted class: graphics
True class: graphics
# Welche beiden Labels wurden vorgeschlagen?
top_labels= exp.available_labels()
# Ausgabe textuell
print ('Explanation for class %s' % class_names[top_labels[0]])
print ('\n'.join(map(str, exp.as_list(top_labels[0]))))
print ()
print ('Explanation for class %s' % class_names[top_labels[1]])
print ('\n'.join(map(str, exp.as_list(top_labels[1]))))
Explanation for class graphics
('with', 0.22280875357861563)
('big', -0.1807320666899509)
('polygons', 0.15856698928030064)
('inside', 0.1286241852179909)
('you', -0.09782679334188744)
('use', 0.09405172204829168)
Explanation for class space
('with', -0.22343255473315313)
('polygons', -0.18450244628432444)
('big', 0.17603735500434836)
('inside', -0.10625047043680522)
('kind', 0.09426451521057765)
('test', 0.08551257639431308)
Positive Evidenzwerte weisen darauf hin, dass das entsprechende Feature für die Klasseneinteilung wichtig war, negative Evidenzwerte sprechen gegen die Klasse. Je größer der absolute Evidenzwert, desto wichtiger das Feature.
Aufgabe: Welche Features sprechen für “graphics” und gleichzeitig gegen “space”? Sind alle Features sofort plausibel?
# Sie können sich die Ausgabe auch visualisieren lassen:
exp.show_in_notebook(text=False)
Aufgabe: Wir haben mit den wichtigsten sechs Features gearbeitet. Trotz TF-IDF-Vektorizer und nachfolgender Feature-Auswahl sind häufige Wörter wie “you” oder “my” in den wichtigen Features übriggeblieben. Sie sind also offensichtlich aussagekräftig, aber für Menschen nicht sehr hilfreich. Gleichzeitig werden die Evidenzwerte immer kleiner; die Features nehmen also an Wichtigkeit ab. Experimentieren Sie mit der Anzahl der zu zeigenden Features: Was scheint Ihnen optimal?
# Wenn Sie sehen wollen, wo im Input die wichtigen Wörter auftauchen:
# 'labels' gibt an, welche Klasse Sie interessiert. Wir wählen die vorhergesagte Klasse 'graphics'.
# Es könnte zur Fehlersuche aber auch eine nicht vorhergesagte Klasse sein. Sie muss allerdings
# in exp.available_labels() sein.
exp.show_in_notebook(text=X_dev[idx], labels=(2,))
3.2. Erklärungen für das ganze Modell#
Um eine Erklärung für die Entscheidungen des ganzen Modells zu bekommen, sieht LIME vor, eine wählbare Anzahl von repräsentativen Instanzen und ihre Erklärungen anzusehen. Hierzu gibt es ein Tutorial, wenn Sie den Ansatz verwenden möchten.
Alternativ können wir auch für einen interessanten Datensatz (z.B. die Entwicklungsdaten) Erklärungen für alle besten Label generieren und jeweils pro Zielklasse die so gefundenen relevanten Features sammeln. So erhalten wir einen Überblick, welche Features für welche Zielklasse positive Evidenz darstellen.
exps_atheism={}
exps_religion={}
exps_space={}
exps_graphics={}
list_of_maps=[exps_atheism, exps_graphics, exps_space, exps_religion]
# Achtung, läuft lange!
for idx in range(0,len(y_dev)):
# Zu kurze Dokumente sorgen für Probleme
if (len(X_dev[idx])<50):
continue
# Das beste Label für jede Instanz erklären
exp = explainer.explain_instance(X_dev[idx], c.predict_proba, num_samples=5000, num_features=6, top_labels=1)
# Die wichtigsten sechs Features für das top_label und ihre Evidenzen (wenn positiv) ablegen
top_label = exp.available_labels()[0]
feature_list = exp.as_list(top_label)
for rep,w in feature_list:
# nur positive Evidenzen zählen
if w<0:
continue
if rep in list_of_maps[top_label]:
list_of_maps[top_label][rep] += w
else:
list_of_maps[top_label][rep] = w
# Klasse "Space"
dict(sorted(exps_space.items(), key=lambda item: item[1], reverse=True))
{'space': 4.532047870117163,
'was': 1.7952088419066035,
'Space': 1.5087167228263463,
'at': 1.4107474316017425,
'orbit': 1.122953355919315,
'they': 1.066846159134587,
'NASA': 1.058761526306829,
'like': 0.9739226082289416,
'year': 0.8200175878963829,
'SPACE': 0.7342959242243406,
'launch': 0.7134721867289163,
'nasa': 0.6643592837659194,
'would': 0.6563739653146742,
'DC': 0.6238978420821393,
'Earth': 0.5785651473830744,
'cost': 0.5712382040648266,
'earth': 0.4734932102257467,
'They': 0.43920723849228593,
'money': 0.412215453086364,
'satellite': 0.4112734649243115,
'be': 0.40229797697325,
'spacecraft': 0.38403398283733603,
'sky': 0.3788112001779861,
'Moon': 0.3760910223608904,
'costs': 0.3589199595997973,
'23': 0.3460880940531164,
'idea': 0.3203928190662413,
'going': 0.31662015443038904,
'someone': 0.30476906753266275,
'wk': 0.29520737559191457,
'thought': 0.28729281304448034,
're': 0.28086461399219187,
'Tommy': 0.2695825988599925,
'mine': 0.26818967733514487,
'off': 0.2539779969250521,
'US': 0.25397510413362623,
'flight': 0.2509219907038118,
'prototype': 0.24411719407734128,
'high': 0.23173264209012573,
'mining': 0.22803066034847405,
'thee': 0.2233969592419174,
'things': 0.2213649213103945,
'shuttle': 0.22059604918370124,
'Griffin': 0.21856837226733108,
'funding': 0.21426481908480527,
'breathing': 0.2063439550913526,
'project': 0.20253029656922206,
'liquid': 0.2013691590690174,
'news': 0.2009954425290026,
'train': 0.2007283853146701,
'remember': 0.2003483221087514,
'resources': 0.19940184508327102,
'Nick': 0.19921039843193383,
'level': 0.19719939947457177,
'quest': 0.19333684210181237,
'orbital': 0.1915771765198837,
'Gehrels': 0.18995132794860725,
'sq': 0.17628657814674656,
'prize': 0.17319274720208874,
'junk': 0.17311444074767204,
'compiler': 0.1725492969366965,
'Germany': 0.16863668277832727,
'right': 0.1632436846726748,
'hover': 0.16291346488440614,
'yo': 0.16195624149718588,
'Tokyo': 0.16061549744229678,
'Shuttle': 0.15953538321561794,
'centaur': 0.15667509177801636,
'error': 0.1551152125760136,
'Galileo': 0.150136785549006,
'clutter': 0.14901614744824332,
'TV': 0.14808361237538414,
'Russians': 0.14459966002262195,
'safety': 0.14199198499754603,
'rid': 0.1410665491667337,
'Imperial': 0.1387749082537866,
'public': 0.13625280731106734,
'Star': 0.13508907145704888,
'News': 0.1342567030677898,
'could': 0.1325708197695111,
'why': 0.13161965112990576,
'Sorry': 0.12950146187329598,
'real': 0.12937838746684271,
'rocket': 0.1276374983705813,
'want': 0.1265103939079867,
'Ti': 0.12491016361925754,
'sorry': 0.12006843291671189,
'Astro': 0.11992279334801018,
'ago': 0.11872365187697809,
'down': 0.118626527980153,
'SSF': 0.1166553960340905,
'process': 0.11662230223687972,
'movie': 0.11628547936976327,
'balloon': 0.11591481344408772,
'citizenship': 0.11591262408577507,
'several': 0.11494400565048418,
'metric': 0.110206110731938,
'credits': 0.10929558084387547,
'80665': 0.10732463472870986,
'dream': 0.10722538174755636,
'beer': 0.10663138374579148,
'networks': 0.1063838531490199,
'Mars': 0.10631593033920891,
'Remember': 0.10534195346866662,
'JOY': 0.10482873606818328,
'needed': 0.10383073669623472,
'who': 0.10352790913866229,
'Shafer': 0.10252267135463812,
'trading': 0.10248167102296296,
'MIssouri': 0.10212269262510601,
'Slight': 0.10172504718730158,
'hit': 0.10122146116697557,
'groups': 0.10113606486542455,
'ATI': 0.10086441101480195,
'liftoff': 0.1007913017183688,
'working': 0.10067330943460012,
'technology': 0.10013141520973275,
'Off': 0.09971848188129419,
'flag': 0.09934701654450778,
'Engineering': 0.09829896050721146,
'rent': 0.09657537113660605,
'multi': 0.09496203067887853,
'Atlanta': 0.09489691941929994,
'being': 0.09372304848582422,
'us': 0.09364163900661063,
'Revolution': 0.09344696444432005,
'contracts': 0.09329237627378885,
'T4': 0.09269070859610452,
'MO': 0.09185029918979135,
'are': 0.09099163632842279,
'miner': 0.0886148038063633,
'Mary': 0.08840197641585106,
'safe': 0.0867442912245114,
'German': 0.08658413908628179,
'much': 0.0863245642747516,
'habitat': 0.08575872075754172,
'Gamma': 0.08563052446344192,
'LOUSY': 0.08438585007826088,
'Bingo': 0.08293826044965313,
'acad3': 0.08288986810590965,
'name': 0.08285654887783382,
'moon': 0.08204332018266637,
'opposite': 0.0816676971969683,
'engineering': 0.08157106677659416,
'timer': 0.08121791860761869,
'solar': 0.08085066139603807,
'sunrise': 0.0804763794594115,
'forever': 0.08044010297634908,
'Pluto': 0.08018874214143355,
'_perijoves_': 0.07983911189672416,
'Air': 0.07939577096668243,
'next': 0.07870806387889878,
'SSTO': 0.07799917695885261,
'data': 0.07788719726709634,
'verse': 0.0774752221067421,
'RE': 0.07736352589721188,
'strings': 0.07723892168033351,
'volumes': 0.07560878056212338,
'Allen': 0.07534099776490392,
'controlled': 0.07496378570231496,
'Dennis': 0.0746723356825329,
'job': 0.07365861260918613,
'subdirectory': 0.07313998316398679,
'turn': 0.07308547803937734,
'pigment': 0.07195492051270508,
'radio': 0.07098704546160226,
'gamma': 0.07081467530317004,
'actually': 0.07047139644500738,
'drag': 0.07046371445066581,
'continuously': 0.07012151133839808,
'longer': 0.06996645243733221,
'sounds': 0.06853133945622618,
'lunar': 0.06814716747949608,
'husc': 0.0676799311678279,
'hours': 0.06746151037070904,
'Red': 0.06719346066382915,
'already': 0.06631503860046205,
'RCS': 0.06629682967594742,
'energy': 0.06589160515991115,
'Happy': 0.06576088589373932,
'rated': 0.06346946533385206,
'cold': 0.06273878613519203,
'sci': 0.06259096080446107,
'distance': 0.06195255603816643,
'Orbit': 0.06180271229354256,
'server': 0.06162774482995932,
'repeating': 0.06122711917343796,
'restored': 0.05985503221031808,
'sideways': 0.05880051689608482,
'SSRT': 0.05830933626662262,
'old': 0.057703332707267976,
'spectroscopy': 0.057624034482713374,
'probe': 0.0554374826117707,
'there': 0.055106637251073405,
'this': 0.05447390930215052,
'forgiving': 0.05354060122450397,
'assuming': 0.0511122250997414,
'posts': 0.050852753205289536,
'development': 0.05064395360354074,
'texture': 0.05020490420335765,
'long': 0.050071443517959294,
'Museum': 0.04989886464988782,
'spent': 0.049462899973688176,
'RS6000': 0.04801373383222361,
'amount': 0.047931893770262655,
'instruct': 0.04739949374227557,
'feasability': 0.04546756683807688,
'mixed': 0.044734664241940135,
'large': 0.0443778606251749,
'idle': 0.04423590392280055,
'Pat': 0.04414872291213584,
'fee': 0.04366890410683535,
'object': 0.043581700037920196,
'advertising': 0.043471865212513054,
'enough': 0.04236923675752747,
'rockets': 0.03985504671581156,
'71': 0.039811454377702254,
'station': 0.03755321431432039,
'beautiful': 0.03753352725606925,
'sacrificed': 0.036693903165812704,
'IMHO': 0.034441843803092315,
'speculation': 0.03384199553681028,
'monitor': 0.03188437493674699,
'Bull': 0.03178236595421966,
'Big': 0.03151074604724656,
'bought': 0.030501941281934623,
'kg': 0.029604468108809547,
'his': 0.029371949069260855,
'solution': 0.02604832051703899,
'Next': 0.025415030475837177,
'music': 0.025394169504314033,
'Crew': 0.02507070108059226,
'Spacecraft': 0.024046638824131477,
'paid': 0.023035036943790926,
'Mae': 0.02261395449183434,
'theme': 0.022516766738568273,
'Some': 0.022237914328946305,
'gravitational': 0.02075811658013823,
'hazardous': 0.020081931674716565,
'ops': 0.019119194986198604,
'Telemetry': 0.018848909313626264,
'LEV': 0.014421098670007734,
'1993': 0.014198850682827552,
'basalts': 0.013685742329467978,
'He': 0.009331096188851277,
'exposure': 0.008557397157597223,
'Fake': 0.008059314748354144,
'Post': 0.007239404092306558,
'Professor': 0.007043384607478397,
'Howell': 0.0048564153306379825,
'maneuver': 0.0025751316210728217,
'Contact': 0.0,
'WATCHMAN': 0.0,
'FELLOWSHIP': 0.0,
'P': 0.0,
'O': 0.0,
'Box': 0.0}
# Klasse "Graphics"
dict(sorted(exps_graphics.items(), key=lambda item: item[1], reverse=True))
{'graphics': 3.5080986666057226,
've': 1.7929969506106638,
'file': 1.759001229017589,
'with': 1.4342617762190055,
'looking': 1.3095130848826109,
'code': 1.0249099150091838,
'files': 1.0078722017902537,
'3D': 0.9991362427254903,
'Thanks': 0.9388351534802534,
'points': 0.9374372047664358,
'image': 0.9267291710260633,
'Hi': 0.9083972861941854,
'anyone': 0.8750155543974407,
'use': 0.8463642881415548,
'program': 0.841034493474195,
'line': 0.7630510138273303,
'Graphics': 0.7591006202442101,
'3DO': 0.7338436896721715,
'Image': 0.6694446095995404,
'package': 0.6620739485427526,
'3d': 0.6565851583330631,
'algorithm': 0.6473620780503233,
'need': 0.6452677506391006,
'sphere': 0.6405715206811039,
'Video': 0.6137974177450181,
'ftp': 0.5821488262487023,
'using': 0.5755612043843596,
'images': 0.5652907263862761,
'POV': 0.5643538295024246,
'computer': 0.5328052403188379,
'info': 0.5234147761285182,
'version': 0.49666457695600275,
'any': 0.48584334770221016,
'68070': 0.47234609468100036,
'format': 0.4302932811481685,
'screen': 0.40810243844088373,
'VGA': 0.3916352942805279,
'works': 0.3831521110365417,
'TIFF': 0.37993514822058405,
'Computer': 0.36304786937060557,
'Windows': 0.35162779696767954,
'polygon': 0.34803464234308534,
'42': 0.3166596260490383,
'video': 0.3047668542708212,
'site': 0.29162502580756766,
'v2': 0.2854116298446577,
'on': 0.2794935893215936,
'PHIGS': 0.2771169654705678,
'CView': 0.27572685522230855,
'PC': 0.270126984693921,
'email': 0.25116020773960934,
'card': 0.24932207853984317,
'thanks': 0.24767833257098493,
'help': 0.2294147570703323,
'work': 0.20907525980893066,
'advance': 0.1934705704550651,
'anybody': 0.19338257523363864,
'epsi': 0.17690123967425028,
'fractal': 0.16970568484715204,
'Info': 0.16519377520957557,
'FTP': 0.1630564141603642,
'Resource': 0.16256305066260981,
'polygons': 0.15951604410457093,
'earlier': 0.15741119441308493,
'home': 0.15543612836184853,
'routine': 0.15479392723937066,
'but': 0.15459489685866035,
'PostScript': 0.15044520828154767,
'available': 0.15014449267651542,
'univesa': 0.146108025436578,
'flights': 0.1454388053592457,
'problem': 0.145385017348585,
'fill': 0.14219889528082966,
'run': 0.14136959073084351,
'Oak': 0.1409214933049736,
'interested': 0.1397096879510309,
'studio': 0.1364299985210549,
'exe': 0.13609580025803275,
'book': 0.13579678872657436,
'amiga': 0.1350393887821389,
'cd': 0.13370691221602013,
'lacks': 0.12946986969828342,
'Any': 0.12778714273706676,
'inside': 0.12586233499840807,
'Book': 0.12550805776470886,
'comp': 0.12542941481711317,
'fine': 0.12448658079812157,
'PLEASE': 0.12029879894236106,
'JPG': 0.11972953619210625,
'able': 0.11972019516087405,
'same': 0.11674886831886307,
'did': 0.11533619392614865,
'GRASP': 0.11507484129045255,
'Version': 0.1149603342277143,
'sunset': 0.11444636576391283,
'vesa': 0.11421769364801367,
'Media': 0.1104601817846318,
'color': 0.10915809112630957,
'archie': 0.10805684504591616,
'tiff': 0.10779708240718106,
'define': 0.10392011891806593,
'bugs': 0.10272527278702233,
'GRaphics': 0.10246009238072061,
'Please': 0.10229471101795735,
'where': 0.10171304498894287,
'used': 0.10103613828483189,
'hidden': 0.100123196141973,
'number': 0.09997743608816688,
'compute': 0.09916482446567594,
'toll': 0.09746474742603009,
'pub': 0.0960760137144048,
'hardware': 0.09547030868125304,
'CD': 0.09303590358052836,
'Apple': 0.09157152099548016,
'desk': 0.08982961644707603,
'Correct': 0.08900015377696134,
'article': 0.0889047670310388,
'courses': 0.08672666798907837,
'gratefull': 0.08522585923717553,
'center': 0.08182654975024767,
'Alice': 0.08144588270101379,
'256': 0.08119072455969725,
'graduate': 0.08085049570523861,
'correct': 0.0807204289475036,
'REINVENTING': 0.08014967506863942,
'Imagine': 0.0799052363080729,
'interface': 0.07834029917389425,
'Siggraph': 0.0768880403148976,
'cview': 0.07662048726599868,
'Color': 0.07505581172815852,
'MPW': 0.0747226128025983,
'UNIX': 0.07401610804888756,
'paste': 0.07302337547553203,
'grabber': 0.07249250903123451,
'Animator': 0.07079398653713956,
'cc': 0.07064530820548108,
'app': 0.0698018591521285,
'just': 0.06969695449360454,
'licensing': 0.06912412570781507,
'preferred': 0.06901415950475037,
'1Mb': 0.06674162193058604,
'TrueColor': 0.06562464525151455,
'Audio': 0.06428484337026018,
'Martin': 0.06370850073912489,
'converter': 0.06203289360314678,
'fix': 0.06164506455649668,
'IMHO': 0.060760269066438714,
'DOS': 0.06035257411143034,
'bitmapped': 0.0596415041636391,
'dot': 0.05926052414117905,
'pardon': 0.057695399058048234,
'group': 0.05739102902019492,
'royalty': 0.0573769805932257,
'rayshade': 0.05673908277557313,
'TSR': 0.054946845025122884,
'library': 0.053723645010919065,
'PEXlib': 0.053639732561005515,
'OAK': 0.051987786523655405,
'SGI': 0.051239028618080974,
'xfig': 0.05107316300584579,
'XV': 0.0506296787178685,
'Borland': 0.04964845209143928,
'cl': 0.049594433939805824,
'improvements': 0.049499510676300616,
'drivers': 0.04910863993427736,
'mini': 0.04903048532336351,
'tha': 0.04856850434915698,
'Gems': 0.04806912593416236,
'390': 0.04794597234322083,
'point': 0.046781756494193354,
'spl': 0.04546655097513189,
'Virtual': 0.04429350842508856,
'strip': 0.04327490545965849,
'Anyone': 0.043180844369582055,
'386': 0.0428659778572691,
'VGALIB': 0.042291355888200835,
'introductory': 0.042037381502842704,
'mode': 0.041728623165051895,
'SVGA': 0.041352746695789304,
'width': 0.04117748486148863,
'viewer': 0.040603972469891954,
'transferring': 0.04033097323934852,
'plane': 0.03889343582613565,
'donations': 0.03888089188490905,
'xview': 0.03769971444072637,
'view': 0.037474560853249655,
'developers': 0.03730450515928311,
'will': 0.03707693606715036,
'intersecting': 0.03621529782192966,
'programmer': 0.03549582016455162,
'Lindley': 0.03499022144958391,
'operational': 0.034401622532891966,
'dont': 0.03425691844096434,
'Databases': 0.03321312737099814,
'organisation': 0.03303037056600581,
'database': 0.0323923979203839,
'height': 0.031036437191772806,
'import': 0.029561922512537624,
'too': 0.028704877921086225,
'hugs': 0.028680813374316334,
'THANKS': 0.028359274809523567,
'Scott': 0.02763737843551621,
'translator': 0.02651376266508327,
'animation': 0.025105896697906464,
'Does': 0.02487216520191594,
'formats': 0.023718633958739622,
'true': 0.023664246348446976,
'Wiley': 0.023485705673325412,
'generating': 0.02184043266594792,
'cjpeg': 0.021800662891677616,
'monitor': 0.02113102739080312,
'Craig': 0.019977647034140865,
'uu': 0.019917722048702808,
'triangle': 0.019487658836645414,
'the': 0.012816380704630587,
'X': 0.008438232677447016,
'hi': 0.005022855607850706,
'128': 0.0046365343358779135,
'FLI': 0.004528275709440822,
'486': 0.004381597116453148,
'and': 0.003996891758702719}
# Klasse "Atheism"
dict(sorted(exps_atheism.items(), key=lambda item: item[1], reverse=True))
{'you': 7.179846414784028,
'not': 2.375555397972572,
'an': 1.6693385368978213,
'religion': 1.5971825182332282,
'what': 1.5293621564059299,
'don': 1.379209390770918,
'Bobby': 1.229498897871446,
'people': 1.1831415242128627,
'atheists': 1.047092683207029,
'posting': 0.9909732518527573,
'motto': 0.9373888989014265,
'must': 0.9184968967458345,
'Islamic': 0.9020239699636885,
'if': 0.8264590005829944,
'TEK': 0.730892015928969,
'You': 0.6255910592038745,
'depression': 0.6220713690627959,
'sex': 0.5987006412881204,
'makes': 0.5852353257620522,
'religious': 0.5644774838677725,
'ICO': 0.532936640813228,
'Cheat': 0.5169651515046064,
'atheist': 0.5035901479652856,
'so': 0.5011700955744158,
'bobbe': 0.4683817466531254,
'simply': 0.4603495988764523,
'risk': 0.4460406523021335,
'Americans': 0.4231122382567475,
'God': 0.4183334583190034,
'wouldn': 0.4179410862462022,
'say': 0.4136159820479897,
'Islam': 0.41359165226629624,
'cause': 0.3926501935688115,
'Bronx': 0.3809769825207555,
'do': 0.3721693033470954,
'cruel': 0.37110986820293884,
'be': 0.3557605532143615,
'isn': 0.34568934895108805,
'your': 0.33701584170379123,
'argument': 0.32531306205959926,
'Bake': 0.3147387870594315,
'Timmons': 0.31427204835258865,
'If': 0.30896009325583007,
'exist': 0.3058955650737567,
'texts': 0.30526156610919486,
'could': 0.29868282697157056,
'agree': 0.29382337107577816,
'she': 0.29262312421856934,
'atheism': 0.2922397396600046,
'Christianity': 0.29003029790453355,
'broken': 0.2879116007407472,
'Satan': 0.2819540680472663,
'false': 0.24790841685908993,
'cannot': 0.23453836738568196,
'we': 0.2240321656243202,
'natural': 0.21617245967900328,
'chance': 0.21159485080283585,
'Atheism': 0.21111599962504893,
'god': 0.20175859264979057,
'Rushdie': 0.2015065938265428,
'him': 0.20034468700123692,
'crime': 0.19917970364005577,
'post': 0.19716981220297425,
'wrong': 0.1966059133223464,
'thing': 0.18854680700662396,
'book': 0.1849273283202136,
'liar': 0.18425464377704184,
'Makes': 0.1832251867946211,
'why': 0.1789953862604463,
'punishment': 0.17621337618929153,
'tells': 0.1676416268024516,
'Kent': 0.1673359811448549,
'eternal': 0.16662263448542822,
'Mary': 0.1658401417137452,
'all': 0.1639839606745131,
'statements': 0.15958046452295377,
'Wingate': 0.15894665270717978,
'HGA': 0.1556086734341902,
'believing': 0.1548987151485588,
'talking': 0.15293856479524867,
'state': 0.15020030995173614,
'Jews': 0.14716506542269406,
'one': 0.1362765924168685,
'explain': 0.1351767340265905,
'Allah': 0.13325383385953568,
'Deletions': 0.1252469608508497,
'no': 0.12469210077563261,
'made': 0.12430784703550563,
'anyway': 0.12094797964434184,
'Hussein': 0.12063409874414868,
'Muslims': 0.11889291737805793,
'being': 0.11628069128341095,
'What': 0.11386828294289601,
'social': 0.11161086800663465,
'relates': 0.1067384174397515,
'fact': 0.10653402625187197,
'oh': 0.10633418333987477,
'science': 0.10629208035732396,
'imply': 0.10603884406171842,
'poster': 0.1043517352249526,
'Must': 0.10393577467212581,
'policy': 0.10274370759412468,
'us': 0.10245022303879413,
'changed': 0.10191076462329861,
'Bible': 0.10152768591059495,
'deletions': 0.10150506629182217,
'mean': 0.10132347582761171,
'laws': 0.09961170213323028,
'worse': 0.09935751028591945,
'most': 0.09329746370314831,
'RELIGION': 0.09168250100774517,
'Atheist': 0.0899743652094988,
'either': 0.08817658312391718,
'belief': 0.08780954072357948,
'Liar': 0.08423321133109449,
'words': 0.08359791700442804,
'deleted': 0.08298591395124817,
'nature': 0.08027494195585375,
'Post': 0.07793651518681326,
'list': 0.07721247131793962,
'moral': 0.07433606444906464,
'however': 0.07313640415750253,
'False': 0.07300692934062286,
'their': 0.0713106914364687,
're': 0.0702547822424798,
'alt': 0.06968768855788068,
'hand': 0.06906211521914174,
'goals': 0.06904170823141513,
'been': 0.06719541743361723,
'give': 0.06653916624120981,
'system': 0.06546629076547,
'everything': 0.06343728557881664,
'which': 0.06341816808188426,
'because': 0.06059047323537425,
'our': 0.059090653519166425,
'can': 0.058527926554770425,
'back': 0.05704346454124428,
'behavior': 0.055185417920686534,
'species': 0.05508451725049218,
'any': 0.054450406299174595,
'Isn': 0.05389702899967399,
'War': 0.05290062715556777,
'Thank': 0.04611643584705191,
'wonder': 0.04370376268452213,
'define': 0.04155555128218039,
'People': 0.041520074438983874,
'cobb': 0.03978436121267461,
'Qur': 0.0357918744386986,
'Who': 0.02825722389695455,
'challenges': 0.026384660114312668,
'Well': 0.024052068291782514,
'on': 0.006533384092447934,
'does': 0.004985196690034595}
# Klasse "Religion"
dict(sorted(exps_religion.items(), key=lambda item: item[1], reverse=True))
{'Jesus': 2.4305219169984706,
'Christian': 2.1991841445791693,
'Christians': 1.9373307886676632,
'objective': 1.8443609345167946,
'he': 1.7711184142601408,
'his': 1.313111148284902,
'who': 1.0399586709031254,
'as': 0.8770164811297377,
'Tyre': 0.8509282580684596,
'He': 0.8226832561779338,
'Mr': 0.8036954178836889,
'God': 0.7880113863794422,
'Kent': 0.7782098244006295,
'me': 0.6856611862392453,
'my': 0.6465753109035555,
'Koresh': 0.5609510034609835,
'children': 0.493637204311162,
'were': 0.47628592096290656,
'Catholic': 0.4724997103816741,
'man': 0.4627144264793609,
'Christ': 0.4515516980109615,
'context': 0.438927103737315,
'with': 0.4187170442196305,
'writes': 0.33958150174284973,
'her': 0.3378993613600558,
'values': 0.32690370058707174,
'humans': 0.3184047219930612,
'may': 0.31420700898558573,
'see': 0.3042525868343142,
'those': 0.29993406756300706,
'bible': 0.28793075127879564,
'My': 0.28750399045829494,
'from': 0.2870282534995917,
'blood': 0.2827877543140119,
'god': 0.27621385865381975,
'GOD': 0.26475499606044683,
'Order': 0.26387874102436454,
'morality': 0.2601822782399365,
'accept': 0.24248843600519293,
'christian': 0.23491354759706518,
'out': 0.2299780294040388,
'no': 0.22805448169844714,
'abortion': 0.22772826299894003,
'deleted': 0.21963990564049485,
'believe': 0.21710740941601925,
'fire': 0.21347713983663943,
'Campbell': 0.2101100051051207,
'FBI': 0.20762300077881476,
'Roehm': 0.20760122564235925,
'Malcolm': 0.20460120507197765,
'hudson': 0.1945156589957093,
'order': 0.19318863844721118,
'non': 0.18122748925814025,
'word': 0.17581978736038242,
'themselves': 0.1621364025849258,
'people': 0.16122080304751626,
'WORD': 0.15440179316121808,
'Sabbath': 0.15385969154784424,
'more': 0.1473577013723517,
'Law': 0.1436625504494542,
'Josephus': 0.14265857341973434,
'cult': 0.1391800641069012,
'Atoms': 0.13846726518227073,
'yourself': 0.13792937262777108,
'atoms': 0.13729952735152232,
'him': 0.13571470922136544,
'Southern': 0.13314031932102996,
'Rosicrucian': 0.13080471558614853,
'sin': 0.12809794623694612,
'Sin': 0.12710662595558198,
'brought': 0.12131195690993742,
'creation': 0.12067591212061286,
'Huh': 0.11704524955314176,
'off': 0.1143742104869438,
'reality': 0.11361086488255288,
'love': 0.11059664741019105,
'smoke': 0.11010638428064218,
'Lord': 0.10686814116603903,
'truth': 0.10397334143824324,
'point': 0.10263626828796904,
'Hudson': 0.10189976991539391,
'John': 0.1014206018478119,
'individual': 0.09729089558647425,
'Please': 0.09587055743450247,
'Brian': 0.09112476130319808,
'threat': 0.08951398240629918,
'salvation': 0.08742344342543766,
'replied': 0.08725382909519466,
'alive': 0.08399082181159616,
'say': 0.08142789161427395,
'wrong': 0.0813448974478324,
'Matthew': 0.08071515788930836,
'your': 0.07929783101779905,
'Rich': 0.07910496693731475,
'Bible': 0.07831304948701236,
'Weiss': 0.07784614830821608,
'taking': 0.07582612976733327,
'Me': 0.07459611307313033,
'Served': 0.0738955939934534,
'public': 0.06700366322941591,
'sort': 0.06696499469925526,
'His': 0.06624143957466556,
'No': 0.066024579282807,
'moral': 0.06313344448705673,
'See': 0.06017556022577749,
'appreciate': 0.05752880294835873,
'Salvation': 0.05673139561852385,
'gas': 0.05441945512750502,
'evidence': 0.054120635637187074,
'Church': 0.05408679608180827,
'now': 0.05342861403316452,
'greatly': 0.04885974482095401,
'question': 0.04625388347310867,
'also': 0.045374534648695196,
'really': 0.04520360311497802,
'church': 0.043462425344967685,
'because': 0.03851719042236228,
'absolute': 0.03765286185946668,
'story': 0.03479600444561077,
'nonsense': 0.032480502906026186,
'Sunday': 0.019356290866473114,
'we': 0.012991346156397417,
'First': 0.012082244667929756,
'are': 0.010198922946877869}
Aufgabe: Schauen Sie sich die indikativsten Features für jede Klasse an. Neben den unterschiedlichen Charakteristika der Texte fällt an den Wörtern selber schnell eine Verbesserungsmöglichkeit auf. Was könnten wir tun, um redundante Features zu vermeiden?